以前、このブログでAWSが推奨するエクスポネンシャル・バックオフとジッターの記事について取り上げ、JavaScriptでの実装をおこないました。
今回は、1度に1リクエストしか処理ができないサービスと複数の競合するクライアントをJavaScriptで用意しました。クライアント数が増えたとき、それぞれのバックオフ・アルゴリズムの処理が完了するまでの総試行回数と処理完了時間がどのように変化するかを確認します。 AWSの記事の最後にあったようなグラフに本当になるのかを試しました。
用意した実装はGitHubに置いてあります。
実装
サービス
index.jsファイルに実装しています。
用意するサービスは1度に1リクエストしか処理できないように排他制御をするので、async-lockというモジュールを利用しました。 async-lockの使い方は以前、当ブログで紹介しています。
Node.jsでasync-lockを使った排他制御をおこなう - s1r-Jの技術ブログ
このサービスは1つのリクエストを平均10ミリ秒(8~12ミリ秒の間でランダム)で処理するように作成しています。
async function request() { await lock.acquire('my-lock', async () => { const request = 10; const fluctuation = 4; await new Promise((resolve) => setTimeout(resolve, request - fluctuation / 2 + Math.random() * fluctuation)); }); }
バックオフとジッターのアルゴリズム
エクスポネンシャル・バックオフ
exponential.jsファイルに実装しています。
リトライ回数に応じて指数関数的に待機時間を伸ばしていくアルゴリズムです。
export default function exponentialBackoff({ base, attempt, cap, }) { return Math.min(cap && Number.MAX_VALUE, base * 2 ** attempt); }
Full Jitter
full.jsファイルに実装しています。
エクスポネンシャル・バックオフで算出された値を最大値とし、最小をゼロとした範囲でランダムに待機時間を決定するアルゴリズムです。
export default function full({ base, attempt, cap, }) { return Math.random() * (Math.min(cap && Number.MAX_VALUE, base * 2 ** attempt)); }
Equal Jitter
equal.jsファイルに実装しています。
エクスポネンシャル・バックオフで算出された値の半分を最大値とし最小をゼロとした範囲でランダムに値を取り出したうえで、エクスポネンシャル・バックオフで算出された値の半分を加えた値を待機時間とするアルゴリズムです。
export default function equal({ base, attempt, cap, }) { const temp = Math.min(cap && Number.MAX_VALUE, base * 2 ** attempt); return temp / 2 + Math.random() * (temp / 2); }
Decorrelated Jitter
decorrelated.jsファイルに実装しています。
前回の待機時間を使って待機時間を算出するアルゴリズムです。 前回の値の3倍の値を最大値とし、最小を初回の待機時間とした範囲でランダムに待機時間を決定します。
export default function decorrelated({ base, cap, prevSleep, }) { return Math.min(cap && Number.MAX_VALUE, base + Math.random() * (prevSleep * 3 - base)); }
実行方法
実行方法はindex.jsファイルを、モード(アルゴリズム)とクライアント数を指定して呼び出します。
$ node index.js <モード> <クライアント数>
例えばFull Jitterでクライアント数10の場合には、以下のようになります。
$ node index.js full 10
測定結果
上記のコードを使って、競合するようにリクエストを発行するクライアント数(client)を増やしたとき、すべてのクライアントの処理が完了するまでにかかる時間(time)と総試行回数(work)の変化を測定しました。
エクスポネンシャル・バックオフ
| client | time(ms) | work |
|---|---|---|
| 1 | 23 | 1 |
| 5 | 193 | 10 |
| 8 | 2657 | 35 |
| 10 | 5194 | 45 |
| 12 | 20580 | 66 |
| 14 | 82063 | 91 |
| 15 | 163983 | 105 |
クライアント数20以上は長くなりすぎるので測定をやめました。
Full Jitter
| client | time(ms) | work |
|---|---|---|
| 1 | 25 | 1 |
| 5 | 278 | 19 |
| 8 | 243 | 34 |
| 10 | 324 | 41 |
| 12 | 330 | 53 |
| 14 | 552 | 73 |
| 15 | 849 | 80 |
| 20 | 911 | 109 |
| 30 | 1195 | 189 |
| 50 | 2959 | 354 |
| 75 | 3813 | 568 |
| 100 | 8040 | 818 |
| 150 | 13775 | 1319 |
| 250 | 27776 | 2408 |
Equal Jitter
| client | time(ms) | work |
|---|---|---|
| 1 | 12 | 1 |
| 5 | 155 | 15 |
| 8 | 375 | 30 |
| 10 | 518 | 50 |
| 12 | 308 | 53 |
| 14 | 993 | 70 |
| 15 | 953 | 76 |
| 20 | 1024 | 110 |
| 30 | 2394 | 183 |
| 50 | 4604 | 351 |
| 75 | 7901 | 561 |
| 100 | 9138 | 805 |
| 150 | 18193 | 1302 |
| 250 | 34653 | 2392 |
Decorrelated Jitter
| client | time(ms) | work |
|---|---|---|
| 1 | 16 | 1 |
| 5 | 159 | 20 |
| 8 | 219 | 41 |
| 10 | 302 | 53 |
| 12 | 613 | 70 |
| 14 | 478 | 89 |
| 15 | 371 | 103 |
| 20 | 655 | 146 |
| 30 | 692 | 250 |
| 50 | 717 | 528 |
| 75 | 2155 | 844 |
| 100 | 5123 | 1253 |
| 150 | 7627 | 2159 |
| 250 | 17154 | 4078 |
グラフ
まず、横軸にリクエストを発行するクライアント数(client)、縦軸に総試行回数(work)をとってプロットしたグラフです。
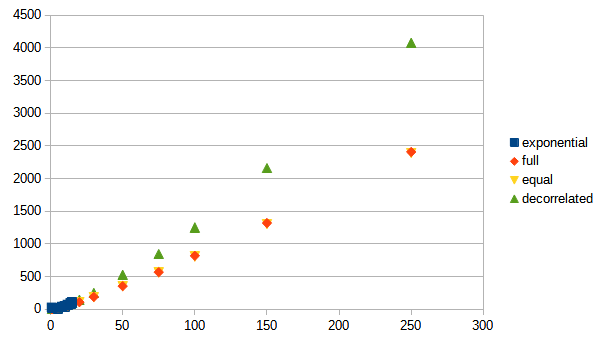
- エクスポネンシャル・バックオフ(exponential)は測定したクライアント数までの範囲では同じくらいだったが、それ以上になるとおそらく劣っていると考えられます(処理時間がかかりすぎるので測定していません)。
- Full Jitter(full)とEqual Jitter(equal)はほぼ同じであり、最も優秀でした。
- Decorrelated Jitter(decorrelated)はFull JitterとEqual Jitterよりも劣っていました。
AWSのブログ記事と同じ結果となりました。
次に、同じく横軸にリクエストを発行するクライアント数(client)、縦軸にはすべてのクライアントの処理が完了するまでにかかる時間(time)をとってプロットしたグラフです。
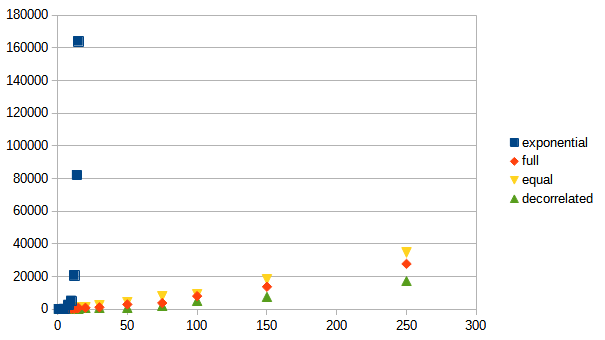
- エクスポネンシャル・バックオフ(exponential)は全くだめで、大きく劣りました。
- 他3つは概ね同じだがDecorrelated Jitter(decorrelated)、Full Jitter(full)とEqual Jitter(equal)の順で優秀でした。
こちらの結果もAWSのブログ記事と同じ結果となりました。
おわりに
というわけで、今回の測定結果から導き出されたアルゴリズムの優劣は、AWSのブログ記事に記載されていたのと同じでした。
こんなざっくりした実装でもアルゴリズムの違いがきちんと反映されて結果に出てきてくれたので、満足です。 新しい発見があったわけではありませんが、再試行処理を実装するさいにはアルゴリズムに気をつけたいと思いました。