AWSにクラウドでの設計・デザインパターンに関する記事があったので、読んでみました。 後で読み返すかもと思って日本語の記事も見てみましたが、機械翻訳しかも文がめちゃくちゃだったので日本語訳してみました。
- 英語のオリジナル記事:Cloud design patterns, architectures, and implementations - AWS Prescriptive Guidance
- 日本語訳の記事:クラウド設計パターン、アーキテクチャ、実装 - AWS の規範的ガイダンス
2023年9月に最終更新されている記事を2023年12月末にアクセスしました。 今後、このガイダンスが更新されると、ここでの訳とズレたり、内容の過不足が起きたりすると思います。
以下、日本語訳です。
クラウド設計パターン、アーキテクチャと実装
はじめに
Anitha Deenadayalan, Amazon Web Services (AWS)
November 2023 (ドキュメント履歴)
このガイドはAWSサービスを利用して一般的に使われるモダナイゼーションデザインパターンを実装するためのガイダンスを提供します。スケーラビリティを実現し、リリース速度を向上させ、変更の影響スコープを縮小し、リグレッションを減少させるために、マイクロサービスアーキテクチャを使ってデザインされたモダンアプリケーションの数は増加しています。この傾向は開発者の生産性の向上、アジリティの上昇、イノベーションの改善、ビジネスニーズへの集中を可能にしています。また、マイクロサービスアーキテクチャはサービスとデータベースにとって最適なテクノロジーの利用をサポートし、ポリグロットコードとポリグロット永続性を推進します。
伝統的に、モノリシックアプリケーションは単一プロセスで動作し、1つのデータストアを使い、垂直スケールするサーバー上で実行されています。一方で、モダンなマイクロサービスアプリケーションはきめ細かく、独立した障害ドメインを持ち、ネットワークを介してサービスとして実行され、ユースケースに依存した1つ以上のデータストアを使うことができます。サービスは水平スケールし、1つのトランザクションが複数のデータベースにまたがることもあります。マイクロサービスアーキテクチャを利用してアプリケーションを開発するさい、開発チームはネットワークコミュニケーション、ポリグロット永続性、水平スケーリング、結果整合性とデータストアをまたがるトランザクションハンドリングに着目する必要があります。そして、モダナイゼーションパターンは、モダンアプリケーション開発で一般的に生じる問題を開発するために必要不可欠であり、ソフトウェアデリバリーを加速させる助けになります。
このガイドは、well-architectedベストプラクティスに基づいたデザインパターンとして正しいクラウドアーキテクチャを選択したいと望むクラウドアーキテクト、テクニカルリード、アプリケーションオーナー、ビジネスオーナー、開発者のために技術的なリファレンスを提供します。本ガイドで議論されているそれぞれのパターンは、マイクロサービスアーキテクチャにおいて1つ以上の既知のシナリオに対応しています。このガイドではそれぞれのパターンに関する問題と注意事項について議論しており、高レベルなアーキテクチャ実装を提供し、パターンのためのAWS実装について記載しています。可能であればオープンソースのGitHubサンプルとワークショップリンクを提供します。
ガイドでカバーするパターンは以下の通り:
- 破損対策レイヤーパターン
- APIルーティングパターン:
- ホスト名ルーティング
- パスルーティング
- ヘッダに基づくルーティング
- サーキットブレーカー
- イベントソーシング
- パブリッシュ・サブスクライブ
- バックオフを伴う再試行
- Sagaパターン:
- Sagaコレオグラフィ
- Sagaオーケストレーション
- ストラングラーフィグ
- トランザクショナルアウトボックス
ターゲットとするビジネス的な成果
自身のアプリケーションをモダナイズするために本ガイドで述べたパターンを使うことで、次のことが可能になります:
- 信頼性が高く、セキュアで、コストとパフォーマンスについて最適な運用効率の高いアーキテクチャを設計および実装すること
- これらのパターンを必要とするユースケースのサイクルタイムを短縮し、代わりに組織固有の変更に集中すること
- AWSサービスを要してパターン実装を標準化することで開発を加速させること
- 技術的負債を継承することなく、開発者にモダンアプリケーションを開発させること
破損対策レイヤーパターン(Anti-corruption layer pattern)
意図
破損対策レイヤーパターン(Anti-corruption layer pattern、ACL)は、あるシステムから別のシステムにドメインモデルのセマンティクスを変換するための中間レイヤーとして動作します。このレイヤーは、上流のアプリケーション開発チームによって規定されたコミュニケーションルールを壊す前に、上流のコンテキスト(モノリス)に依存したモデルを下流のコンテキスト(マイクロサービス)に適したモデルに変換します。このパターンは下流のコンテキストにコアサブドメインが含まれている場合や、上流のモデルが変更不可能なレガシーシステムである場合に適用できます。また、呼び出しがターゲットシステムに透過的にリダイレクトされる必要がある場合、呼び出し元を変更することを防ぐことで、変更リスクとビジネス中断を減らすことができます。
動機
移行プロセスにおいて、モノリシックアプリケーションがマイクロサービスに移行されるとき、新しく移行されるサービスのドメインモデルのセマンティクスに変更があるかもしれない。モノリスの機能がマイクロサービスを呼び出すために必要な場合、サービスの呼び出し方法に変更を加えることなく移行先サービスに呼び出しをルーティングするべきです。ACLパターンは新しいセマンティクスに呼び出しを変換するアダプターまたはファサードレイヤーとして動作することで、モノリスが透過的にマイクロサービスを呼び出すことを可能にします。
適用
次のような場合にパターンの利用を検討します:
- 既存のモノリシックアプリケーションがマイクロサービスに移行された機能と通信する必要があり、移行されたサービスのドメインモデルとセマンティクスが元の機能と異なる場合
- 2つのシステムは異なるセマンティクスを持ち、データを交換する必要があるが、一方のシステムをもう一方のシステムと互換性を持つように修正するのは現実的ではない場合
- 一方のシステムをもう一方のシステムに適合させるために、影響を最小限に抑えながら迅速でシンプルなアプローチを使用したい場合
- アプリケーションが外部システムと通信している場合
問題と注意事項
- チーム依存:システム内の異なるサービスが異なるチームに管理されている場合、移行するサービスの新しいドメインモデルのセマンティクスは呼び出し元のシステムに変更をもたらす可能性があります。しかし、協調的に変更することはできないかもしれません、他の優先事項があるためです。ACLは呼び出される側を分離し、新しいサービスのセマンティクスに適合するように呼び出しを変換します、つまり既存システムの呼び出し元を変更する必要をなくします。
- 運用オーバーヘッド:ACLパターンは追加の運用と維持を必要とします。この作業には、ACLを監視・アラートツール、リリースプロセスや継続的インテグレーションおよび継続的デリバリー(CI/CD)と連携させることも含みます。
- 単一障害点:ACLで発生した障害はターゲットサービスを到達不可にし、アプリケーション障害を引き起こします。この問題を緩和するには、再試行機能とサーキットブレーカーを作成する必要があります。これらの選択肢についての詳細は、バックオフを伴う再試行パターンおよびサーキットブレーカーパターンをご覧ください。適切なアラートとロギング設定は、平均修理時間(MTTR)を改善するでしょう。
- 技術的負債:移行またはモダナイゼーション戦略の一部として、ACLは一時的または暫定的なソリューションなのか、長期的なソリューションなのかを検討してください。もし、暫定的なソリューションの場合、ACLを技術的負債として記録するべきであり、依存している呼び出し元がすべて移行したあとは廃止されるべきです。
- レイテンシ:追加レイヤーはリクエストのインタフェースを変換するためにレイテンシを追加する可能性があります。本番環境にACLをデプロイする前に、応答時間に敏感なアプリケーションでパフォーマンス耐性を定義してテストするを推奨します。
- スケーリングボトルネック:サービスがピーク負荷時にスケールする高負荷アプリケーションの場合、ACLがボトルネックとなり、スケーリング障害を引き起こす可能性があります。ターゲットサービスが需要によってスケールする場合、ACLもあわせてスケールするように設計すべきです。
- サービス固有またはサービス共有の実装:複数のサービスやサービス固有クラスに呼び出しを変換およびリダイレクトする共有オブジェクトとしてACLを設計することができます。ACLの実装方法を決定する場合、レイテンシ、スケーリング、障害耐性を考慮にいれてください。
実装
ACLは、モノリシックなアプリケーションの内部に移行するサービス固有のクラスとして実装することも、独立したサービスとしても実装することができます。ACLはすべての依存したサービスがマイクロサービスアーキテクチャに移行したあと、廃止されなければなりません。
高レベルアーキテクチャ
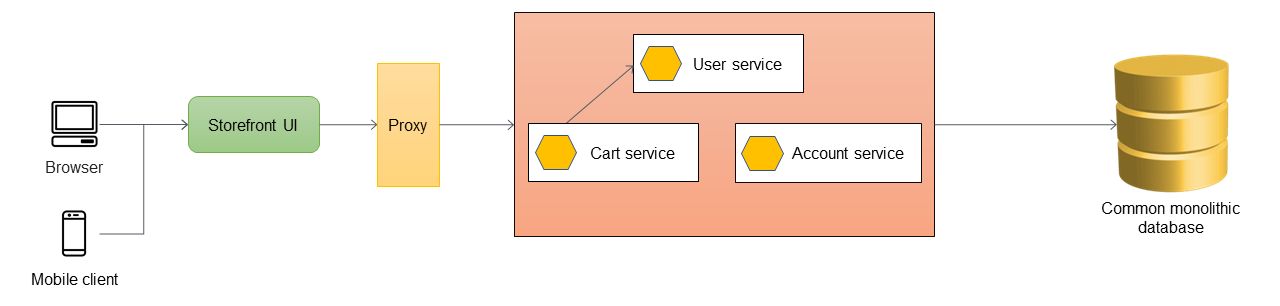
以下のアーキテクチャ例では、モノリシックなアプリケーションは3つのサービスを持ちます:userサービス、cartサービス、そしてaccountサービス。cartサービスはuserサービスに依存し、アプリケーションはモノリシックなリレーショナルデータベースを利用しています。

以下のアーキテクチャでは、userサービスが新しいマイクロサービスに移行しました。cartサービスがuserサービスを呼び出しますが、実装はモノリス内部で既に利用できません。また、新規移行サービスのインタフェースは文理シックなアプリケーション内部にあったときの従来インタフェースと一致しません。
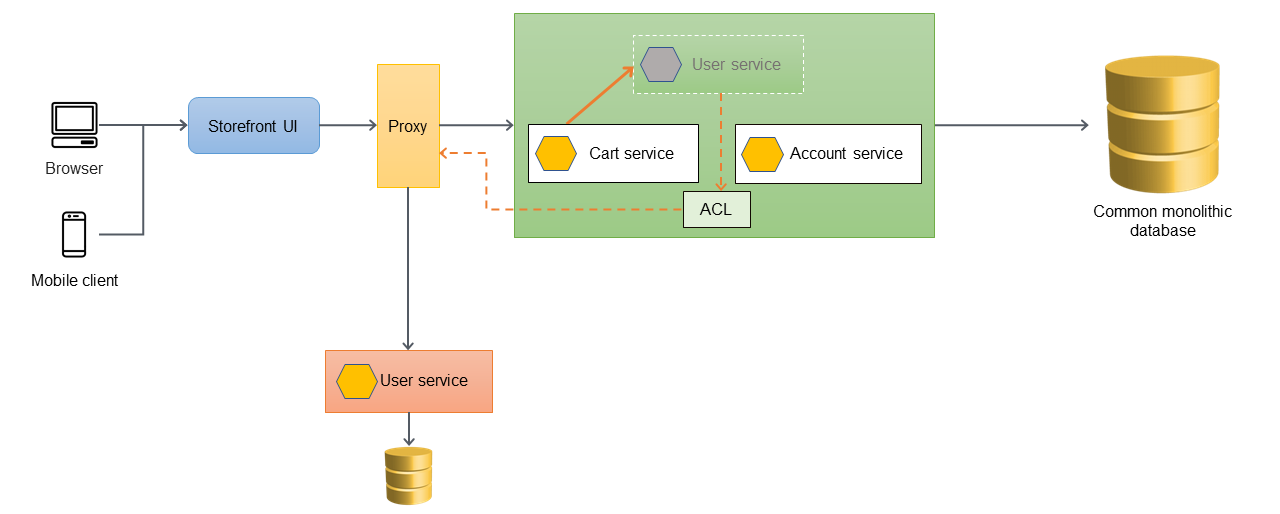
cartサービスが新規移行userサービスを直接呼び出す必要がある場合、cartサービスを変更する必要があり、モノリシックなアプリケーションの全体テストが必要です。これは移行リスクとビジネス的な混乱を増加させる可能性があります。目的は、モノリシックなアプリケーションの既存機能の変更を最小限にすることです。
このケースでは、旧userサービスと新規移行userサービスの間にACLを導入することを推奨します。ACLは新しいインタフェースのために呼び出しを変換するアダプターまたはファサードとして動作します。ACLはモノリシックなアプリケーション内部の移行したサービス固有のクラス(例えば、UserServiceFacadeやUserServiceAdapter)として実装されるでしょう。破損対策レイヤーははすべての依存したサービスがマイクロサービスアーキテクチャに移行したあと、廃止されなければなりません。

AWSサービスを利用した実装
以下のダイアグラムは、AWSサービスを利用したACLの実装例を示しています。
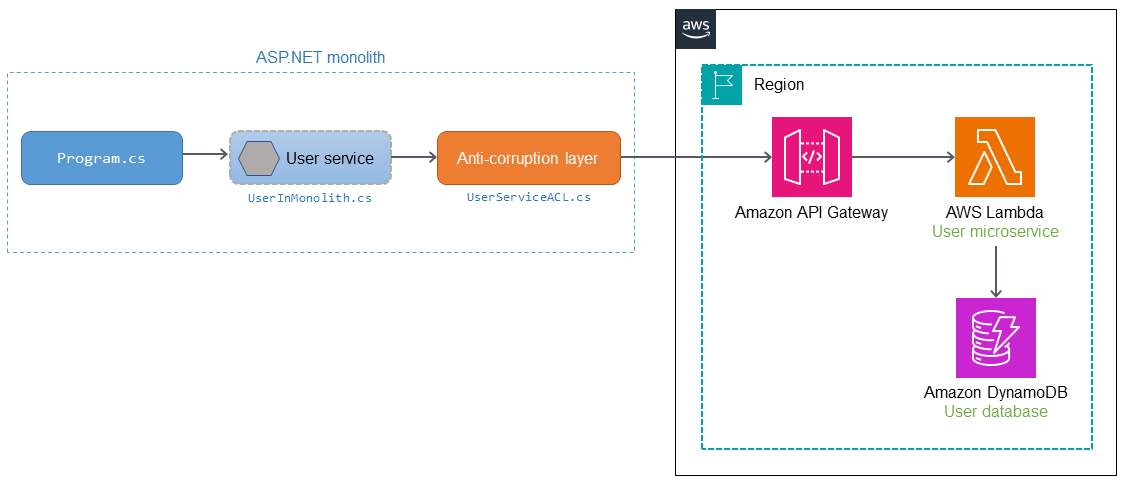
userマイクロサービスはASP.NETモノリシックアプリケーションから移行し、AWS上のAWS Lambda関数としてデプロイされます。Lambda関数への呼び出しはAmazon API Gatewayを介してルーティングされます。ACLはモノリス内部にデプロイされ、userマイクロサービスのセマンティクスに適合するように呼び出しを変換します。
モノリス内部でProgram.csがuserサービス(UserInMonolith.cs)を呼び出す場合、呼び出しはACL(UserServiceACL.cs)にルーティングされます。ACLは呼び出しを新しいセマンティクスとインタフェース向けに変換し、API Gatewayエンドポイントを介してマイクロサービスを呼び出します。呼び出し元(Program.cs)はuserサービスとACLで実行される変換およびルーティングを意識していません。呼び出し側はコード変更を意識していないため、ビジネス的な混乱や移行リスクは小さくなります。
サンプルコード
以下のコードスニペットは従来のサービスへの変更とUserServiceACL.csの実装を示しています。リクエストを受け取ったさい、従来のuserサービスはACLを呼び出します。ACLはソースオブジェクトを、新規移行サービスのインタフェースに合致するように変換し、サービスを呼び出し、呼び出し元にレスポンスを返します。
public class UserInMonolith: IUserInMonolith { private readonly IACL _userServiceACL; public UserInMonolith(IACL userServiceACL) => (_userServiceACL) = (userServiceACL); public async Task<HttpStatusCode> UpdateAddress(UserDetails userDetails) { //Wrap the original object in the derived class var destUserDetails = new UserDetailsWrapped("user", userDetails); //Logic for updating address has been moved to a microservice return await _userServiceACL.CallMicroservice(destUserDetails); } } public class UserServiceACL: IACL { static HttpClient _client = new HttpClient(); private static string _apiGatewayDev = string.Empty; public UserServiceACL() { IConfiguration config = new ConfigurationBuilder().AddJsonFile(AppContext.BaseDirectory + "../../../config.json").Build(); _apiGatewayDev = config["APIGatewayURL:Dev"]; _client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json")); } public async Task<HttpStatusCode> CallMicroservice(ISourceObject details) { _apiGatewayDev += "/" + details.ServiceName; Console.WriteLine(_apiGatewayDev); var userDetails = details as UserDetails; var userMicroserviceModel = new UserMicroserviceModel(); userMicroserviceModel.UserId = userDetails.UserId; userMicroserviceModel.Address = userDetails.AddressLine1 + ", " + userDetails.AddressLine2; userMicroserviceModel.City = userDetails.City; userMicroserviceModel.State = userDetails.State; userMicroserviceModel.Country = userDetails.Country; if (Int32.TryParse(userDetails.ZipCode, out int zipCode)) { userMicroserviceModel.ZipCode = zipCode; Console.WriteLine("Updated zip code"); } else { Console.WriteLine("String could not be parsed."); return HttpStatusCode.BadRequest; } var jsonString = JsonSerializer.Serialize<UserMicroserviceModel>(userMicroserviceModel); var payload = JsonSerializer.Serialize(userMicroserviceModel); var content = new StringContent(payload, Encoding.UTF8, "application/json"); var response = await _client.PostAsync(_apiGatewayDev, content); return response.StatusCode; } }
GitHubリポジトリ
このパターンのサンプルアーキテクチャの実装全体は、GitHubリポジトリhttps://github.com/aws-samples/anti-corruption-layer-patternをご確認ください。
関連するコンテンツ
APIルーティングパターン(API routing patterns)
アジャイル開発環境では、自律的なチーム(例えばスクアッドやトライブ)が、多くのマイクロサービスを含む1つ以上のサービスを所有します。チームはこれらのサービスをAPIとして公開し、コンシューマがサービス群やアクション群とインタラクトできるようにします。
ホスト名とパスを使って上流のコンシューマにHTTP APIを公開する代表的な3つの方式があります:
| 方式 | 詳細 | 例 |
|---|---|---|
| ホスト名ルーティング(Hostname routing pattern) | 各サービスをホスト名を使って公開する | billing.api.example.com |
| パスルーティング(Path routing) | 各サービスをパスを使って公開する | api.example.com/billing |
| ヘッダに基づくルーティング(Header-based routing) | 各サービスをヘッダを使って公開する | x-example-action: something |
このセクションでは、これら3つのルーティング方式のどれが自分たちの要件と組織構造に最適なのかを判断するのに役立つ、典型的なユースケースとトレードオフについて紹介します。
ホスト名ルーティング
ホスト名によるルーティングは、各APIに独自のホスト名を与えることでAPIサービスを分離する仕組みです;例えば、service-a.api.example.comやservice-a.example.comのように。
典型的なユースケース
ホスト名を使ったルーティングでは、サービスチーム間で共有するものがないため、リリースでの競合を減らすことができます。チームはDNSエントリから本番環境でのサービス運用まですべての監理に責任を持ちます。

長所
ホスト名ルーティングは、HTTP APIルーティングとして最も単純でスケーラブルな方式です。この方式に従ったアーキテクチャを構築するために関連したAWSサービスを自由に使うことができます―Amazon API Gateway、AWS AppSync、Application Load BalancerとAmazon Elastic Compute Cloud (Amazon EC2)またはHTTPに準拠したサービスをアーキテクチャを作成することができます。
チームはホスト名ルーティングを使用して、サブドメインを完全に所有することができます。また、特定のAWSリージョンやバージョン(例えば、region.service-a.api.example.comやdev.region.service-a.api.example.com)のためにデプロイメントを分離、テスト、オーケストレーションすることが容易になります。
短所
ホスト名ルーティングを利用する場合、コンシューマは公開する各APIにインタラクトするために異なるホスト名を覚えておく必要があります。クライアントSDKを提供することで、この問題を軽減できます。
しかし、クライアントSDKには課題があります。例えば、ローリングアップデート、多言語対応、バージョニング、セキュリティ問題やバグ修正による破壊的変更に関する通知、ドキュメンテーションなどをサポートしなければなりません。
パスルーティング
パスによるルーティングは、同じホスト名の下にある複数または全てのAPIをグルーピングし、サービスを分割するためにリクエストURIを利用する仕組みです;例えばapi.example.com/service-aとapi.example.com/service-bのように。
典型的なユースケース
ほとんどのチームはシンプルなアーキテクチャを要望するため、この方式を選択します―HTTP APIとインタラクトするために開発者はapi.example.comのようなたった1つのURLを覚えておく必要があります。APIドキュメントは多くの場合で異なるポータルやPDFに分割されることなく、一緒に監理されているため、理解しやすいことが多いです。
パスに基づくルーティングは、HTTP APIを共有すうためにシンプルな仕組みと考えられています。しかし、設定、認可統合、複数のホップによる追加レイテンシのような運用上のオーバーヘッドが含まれます。また、設定ミスがすべてのサービスの中断とならないように、成熟した変更管理プロセスが必要になります。
AWSでは、APIを共有し、正しいサービスに効率的にルーティングするための複数の方法があります。以下のセクションでは、3つのアプローチについて議論します:HTTPサービスリバースプロキシ、API GatewayそしてAmazon CloudFrontです。AWS上で稼働する下流サービスに依存しているような、APIサービスの統合のためのアプローチはありません。サービスはHTTPに準拠するかぎり、どこでも問題なく、どのようなテクノロジーでの実行できます。
HTTPサービスリバースプロキシ
動的なルーティング設定を作成するため、NGINXのようなHTTPサーバーを使うことができます。Kubernetesアーキテクチャでは、サービスへのパスに一致するIngressルールを作成することもできます(本ガイドではKubernetesIngressについてはカバーしません;詳細はKubernetesドキュメントを参照してください)。
以下の設定は、NGINXのapi.example.com/my-service/のHTTPリクエストからmy-service.internal.api.example.comへの動的マップです。
server {
listen 80;
location (^/[\w-]+)/(.*) {
proxy_pass $scheme://$1.internal.api.example.com/$2;
}
}
以下のダイアグラムはHTTPサービスリバースプロキシ方式を表しています。
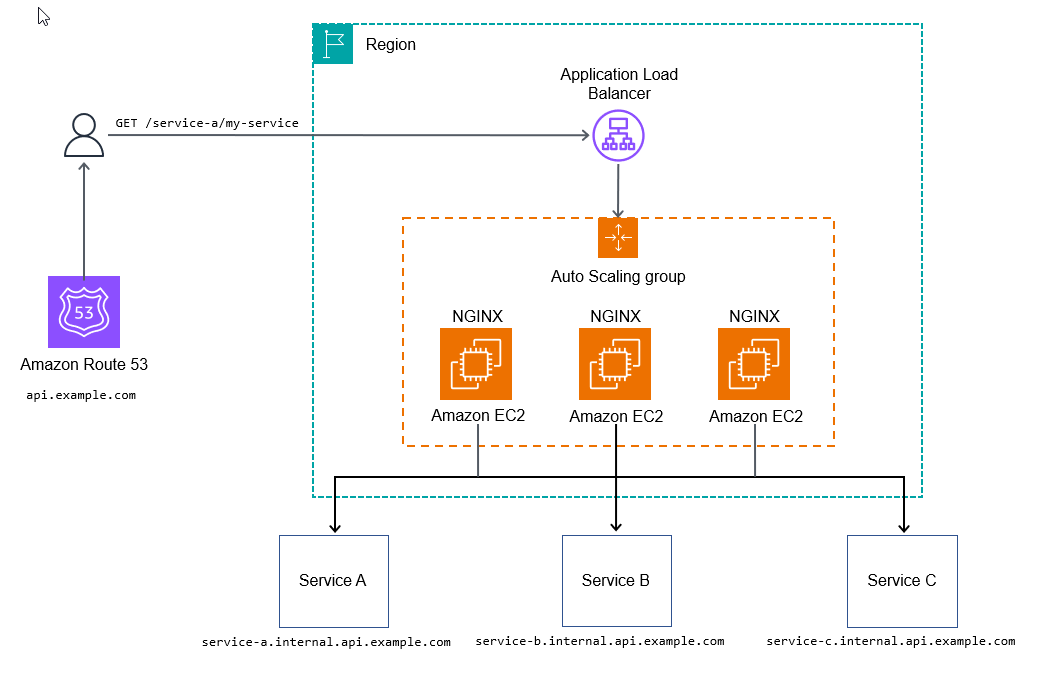
このアプローチは、下流のAPIにメトリクスやログを収集させるため、リクエスト処理を開始するために追加設定が必要ないユースケースでは充分と考えられます。
本番環境での運用準備のため、スタックの各レベルに観測可能性を追加したり、追加設定を増やしたり、レート制限や利用トークンなどのより高度な機能を使えるようにするためにAPIイングレスポイントをカスタマイズするスクリプトを追加したりできるようにしたいはずです。
# 長所
HTTPサービスリバースプロキシは究極の狙いは、APIを単一ドメインに統合するためのスケーラブルで管理しやすいアプローチを作成することであり、どのようなAPIコンシューマでの一貫して見えるようにすることです。また、このアプローチは、サービスチームが独自のAPIをデプロイ後のオーバーヘッドを最小にしてデプロイおよび管理することを可能にします。AWS X-RayやAWS WAFのようなAWSが管理するトレースサービスを利用することもできます。
# 短所
このアプローチの主たる欠点は、インフラストラクチャコンポーネントの大規模なテストと管理が必要となることですが、サイト信頼性エンジニアリング(SRE)チームがある場合には問題にならないでしょう。
この方式にはコストの転換点があります。小規模や中規模の場合、このガイドで議論している他の方式よりも高価になります。大規模(およそ毎秒100Kトランザクション以上)の場合には非常にコスト効率がよくなります。
API Gateway
Amazon API Gatewayサービス(REST APIおよびHTTP API)はHTTPサービスリバースプロキシ方式と似た方法でトラフィックをルーティングすることができます。HTTPプロキシモードでAPI Gatewayを利用すると、多くのサービスをトップレベルサブドメインapi.example.comにエントリーポイントをラップし、ネストされたサービスにリクエストをプロキシするシンプルな方法を提供します。
ルートまたはコアとなるAPI Gatewayですべてのパスとすべてのサービスをマッピングするような細かすぎるマッピングはしたいと思わないでしょう。代わりに、/billing/*のようなワイルドカードパスを選んでリクエストをbillingサービスに転送することができます。ルートまたはコアとなるAPI Gatewayですべてのパスをマッピングしないことで、APIを変更するたびにAPI Gatewayを更新する必要がなくなるため、APIに対して柔軟性を得ることができます。
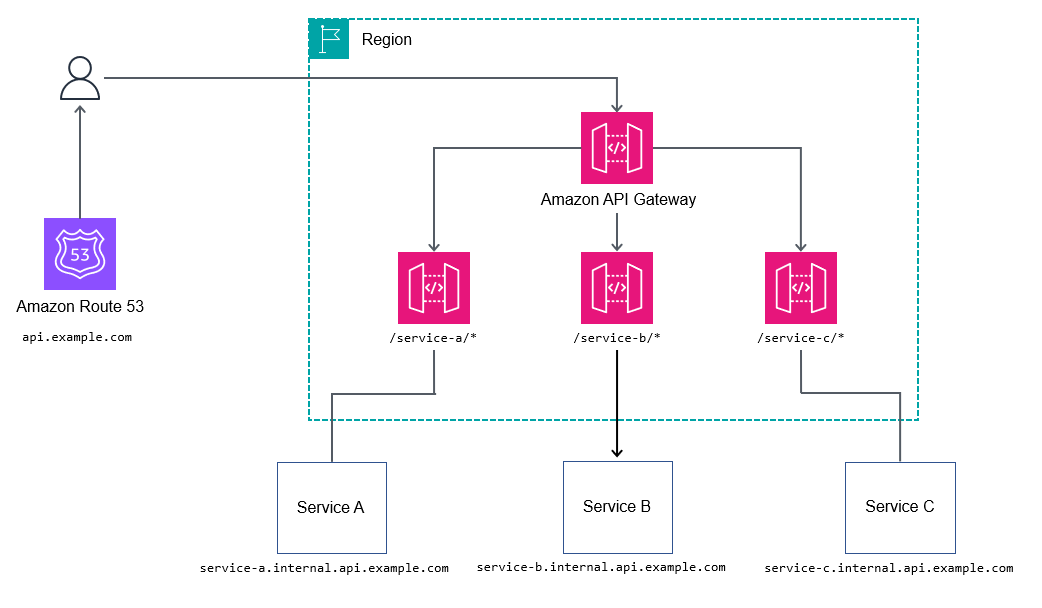
# 長所
例えば、リクエスト属性を変更するようなより複雑なワークフローを制御するため、REST APIはApache Velocity Template Language(VTL)を公開し、リクエストとレスポンスを変更可能にできます。REST APIはさらに以下のような追加の利点があります:
- AWS Identity and Access Management(IAM)、Amazon CognitoやAWS Lambdaオーサライザーによる認証・認可
- トレースのためのAWS X-Ray
- AWS WAFとの統合
- 基本的なレート制限
- 異なるティアにコンシューマを分類するための利用トークン(API GatewayドキュメントのThrottle API requests for better throughputを参照)
# 短所
大規模な場合、コストが問題になるかもしれません。
Amazon CloudFront
条件に応じてオリジン(サービス)を選択してリクエストを転送するため、Amazon CloudFrontの動的オリジン選択機能を使うことができます。api.example.comのような単一のホスト名を介して多数のサービスにルーティングするためにこの機能を使うことができます。
# 典型的なユースケース
ルーティングロジックはLambda@Edge関数内のコードとして存在するため、A/Bテスト、カナリアリリース、機能フラグ、パスの書き換えなどの高度にカスタマイズ可能なルーティングメカニズムをサポートします。以下の図に示します。
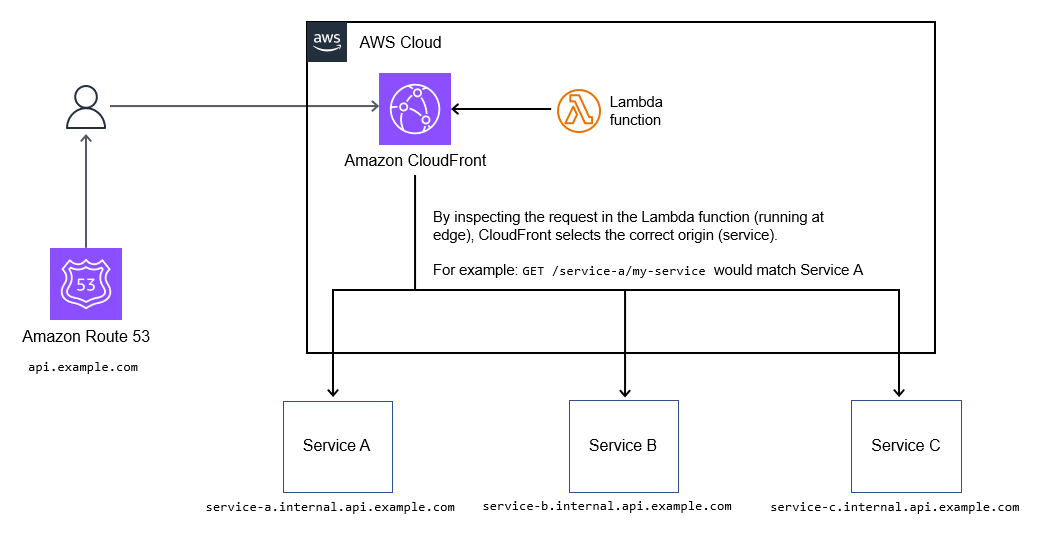
# 長所
APIレスポンスをキャッシュする必要がある場合、この方式は単一のエンドポイントの背後にあるサービス群を統合するのに適しています。API群を統合する費用対効果が高い方式です。
また、CloudFrontは基本的なレート制限と基本的なACLのためのAWS WAFとの統合だけでなく、フィールドレベルの暗号化をサポートしています。
# 短所
この方式は、統合できるオリジン(サービス)を最大250までサポートします。ほとんどのデプロイメントではこの制限で充分ですが、サービスのポートフォリオが大きくなるにつれて多数のAPIが問題を引き起こす可能性があります。
Lambda@Edge関数の更新には現状数分かかります。また、CloudFrontもすべてのプレゼンスポイントへの変更の伝播が完了するまで最大30分かかります。これは更新が完了するまでそれ以降の更新をブロックすることになります。
ヘッダに基づくルーティング
ヘッダに基づくルーティングでは、HTTPリクエストのHTTPヘッダを指定することで、各リクエストに対して正しいサービスをターゲットにすることができます。例えば、x-service-a-action: get-thingというヘッダを送ると、Service Aからget thingの結果を取得できます。どのリソースを操作しようとしているのかを示唆するため、ここでもリクエストのパスは重要です。
アクションのためにHTTPヘッダールーティングを使うことに加えて、バージョンルーティング、機能フラグの有効化、A/Bテスト、または同様のニーズのための仕組みとして使うことができます。実際には、堅牢なAPIを作成するためにヘッダルーティングを他のルーティング方式と併用することになるでしょう。
HTTPヘッダルーティングのアーキテクチャは通常、以下の図のように、マイクロサービスの前に正しいサービスにルーティングしてレスポンスを返す薄いルーティングレイヤーを持ちます。このルーティングレイヤーはすべてのサービスをカバーすることもでき、バージョンに基づくルーティングのようなオペレーションを可能にするためにいくつかのサービスだけをカバーすることもできます。
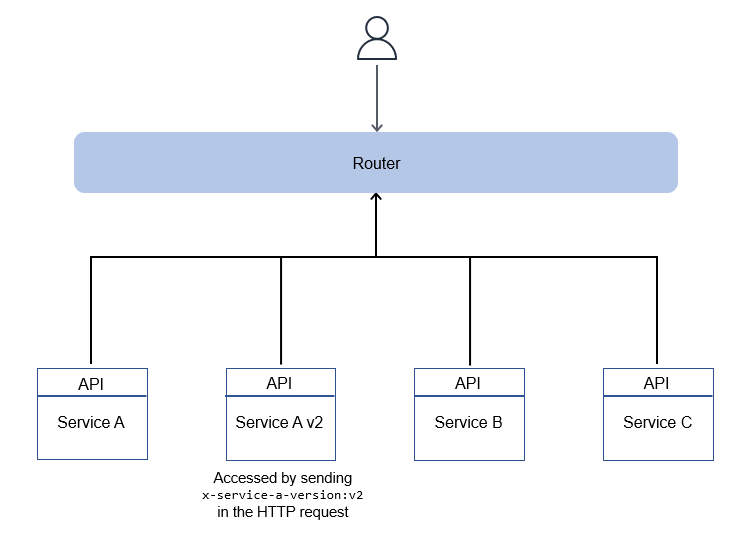
長所
設定変更は最小限の労力で済み、簡単に自動化できます。また、この方式は柔軟性があり、サービスに必要な特定の操作のみを公開する方法をサポートします。
短所
ホスト名ルーティング方式と同様に、HTTPヘッダに基づくルーティングはクライアントを完全に制御し、カスタムHTTPヘッダを操作できることを前提としています。プロキシ、コンテンツデリバリーネットワーク(CDN)、ロードバランサーは、ヘッダサイズを制限する可能性があります。まずないことですが、追加するヘッダやクッキーの数によっては問題になる可能性があります。
サーキットブレーカーパターン(Circuit breaker pattern)
意図
サーキットブレーカーパターンは、呼び出しが過去に繰り返しタイムアウトまたは失敗している場合に、呼び出し元サービスが別のサービス(呼び出し先)への呼び出しを再試行することを防ぎます。このパターンは、呼び出し先のサービスが再び機能するタイミングを検知するためにも利用されます。
動機
複数のマイクロサービスが連携してリクエストを処理する場合、1つ以上のサービスが利用できなくなったり、遅延が大きくなったりする可能性があります。複雑なアプリケーションでマイクロサービスを採用する場合、1つのマイクロサービスでの障害がアプリケーションの障害につながる可能性があります。マイクロサービスはリモートプロシージャコールを介して通信するため、ネットワーク接続での一過性のエラーが障害となる可能性があります。(一時的なエラーは、バックオフを伴う再試行パターンで対処できます)。同期実行中に、タイムアウトや障害がカスケード的に発生するとユーザーエクスペリエンスが低下する可能性があります。
しかし、例えば呼び出し先サービスがダウンしていたり、データベースの競合によりタイムアウトが発生していたりする場合、障害の解決に時間がかかるケースがあります。このようなケースでは、呼び出し元サービスが何度も呼び出しを再試行すると、ネットワークの競合やデータベースのスレッドプールの消費につながる可能性があります。さらに、複数のユーザーがアプリケーションを繰り返し再試行する場合、これは問題を悪化させ、アプリケーション全体のパフォーマンス低下を引き起こす可能性があります。
サーキットブレーカーパターンは、Michael Nygardが『Release It』(Nygard 2018)で紹介しました。このデザインパターンは、呼び出し元サービスからの過去にタイムアウトや失敗を繰り返したサービス呼び出しを再試行するのを防ぐことができます。また、呼び出し先のサービスが再び機能するタイミングを検出することもできます。
サーキットブレーカーオブジェクトは、回路に異常が発生すると自動的に電流を遮断する電気回路遮断器のように動作します。電気回路ブレーカーは、障害が発生すると電流の流れを遮断(トリップ)します。同様に、サーキットブレーカーオブジェクトは呼び出し元と呼び出し先のサービスの間に位置し、呼び出し先が利用できない場合にトリップします。
分散コンピューティングの落とし穴とは、サン・マイクロシステムズのPeter Deutschらによる一連の主張です。彼らによれば、分散アプリケーションを初めて使うプログラマーは、必ず誤った見積もりをするということです。ネットワークの信頼性、ゼロレイテンシへの期待、帯域幅制限によって、ネットワークエラーに対する最小限のエラー処理で書かれたソフトウェアアプリケーションになってしまうのです。
ネットワークが停止している間、アプリケーションは応答を無期限に待ち続け、アプリケーションリソースを消費し続けるかもしれません。ネットワークが利用可能になったときに操作を再試行しないことも、アプリケーションの劣化につながります。ネットワークの問題でデータベースや外部サービスへのAPIコールがタイムアウトすると、サーキットブレーカーがない状態で呼び出しが繰り返され、コストとパフォーマンスに影響を与える可能性があります。
適用
このパターンを使うのは以下の場合です:
- 呼び出し元サービスが、失敗する可能性の高い呼び出しをおこなう場合
- 呼び出し先サービスのレイテンシが長く(データベース接続が遅い場合など)、呼び出し先サービスがタイムアウトする場合
- 呼び出し元サービスが同期的呼び出しをおこなうが、呼び出し先サービスが利用できない、またはレイテンシが長い場合
問題と注意事項
- サービスに依存しない実装:コードの肥大化を防ぐため、サーキットブレーカーオブジェクトはマイクロサービスにとらわれず、API駆動方式で実装することを推奨します。
- 呼び出し先での回路クローズ:呼び出し先がパフォーマンスの問題や障害から回復すると、ステータスを
CLOSEDに更新できます。これはサーキットブレーカーパターンの拡張であり、回復時間目標(RTO)が必要な場合に実装できます。 - マルチスレッド呼び出し:有効期限タイムアウト値は、サービスの可用性をチェックするために呼び出しを再試行するまで回路をトリップしたままにする期間です。呼び出し先サービスが複数のスレッドで呼び出される場合、最初に失敗し呼び出しが有効期限タイムアウト値を定義します。実装では、後続の呼び出しによって有効期限タイムアウトが変更されないようにする必要があります。
- 強制的にサーキットをオープンまたはクローズする:システム管理者は、回路を開いたり閉じたりする機能を持つべきです。これは、データベースのテーブルの有効期限タイムアウト値を更新することで実行されます。
- 観測可能性:アプリケーションは、サーキットブレーカーが開いているときに失敗したコールを特定するために、ロギングを設定すべきです。
実装
高レベルアーキテクチャ
以下の例では、呼び出し元はorderサービスであり、呼び出し先がpaymentサービスとなっています。
障害がない場合、orderサービスは図のように、サーキットブレーカーによってpaymentサービスにすべての呼び出しがルーティングされます。

paymentサービスがタイムアウトしている場合、サーキットブレーカーはタイムアウトを検知し、障害を追跡します。

タイムアウトが特定の閾値を超えると、アプリケーションはサーキットを開きます。サーキットが開いている場合、サーキットブレーカーオブジェクトはpaymentサービスに呼び出しをルーティングします。サーキットブレーカーオブジェクトはorderサービスがpaymentサービスを呼び出す際に即座に失敗を返します。
サーキットブレーカーオブジェクトは、paymentサービスへの呼び出しが成功するかを確認するため、定期的に施行します。

paymentサービスへの呼び出しが成功した場合、サーキットは閉じられ、他すべての呼び出しを再びpaymentサービスにルーティングします。

AWSサービスを利用した実装
サンプルソリューションでは、AWS Step Functionsのexpressワークフローを使用してサーキットブレーカーパターンを実装しています。Step Functionsのステートマシンを使用すると、パターンの実装に必要な再試行機能と決定ベースの制御フローを構成できます。
また、このソリューションでは回路ステータスを追跡するためのデータストアとしてAmazon DynamoDBのテーブルを使用しています。パフォーマンスを向上させるために、Amazon ElastiCache for Redisなどのインメモリデータストアに置き換えることができます。
あるサービスが他のサービスを呼び出したい場合、呼び出し先サービスの名称を指定してワークフローを開始します。ワークフローは、DynamoDBのCircuitStatusテーブルからサーキットブレーカーのステータスを取得します。CircuitStatusに呼び出し先の有効期限内のレコードが含まれている場合、回線は開いています。Step Functionsワークフローは即座に失敗を返し、FAIL状態で終了します。
CircuitStatusテーブルに呼び出し先のレコードがないか、期限切れのレコードがある場合、サービスは稼働中です。ステートマシン定義のExecuteLambdaステップは、パラメータ値を通じて送信されたLambda関数を呼び出します。呼び出しが成功すると、Step FunctionsワークフローはSUCCESS状態で終了する。
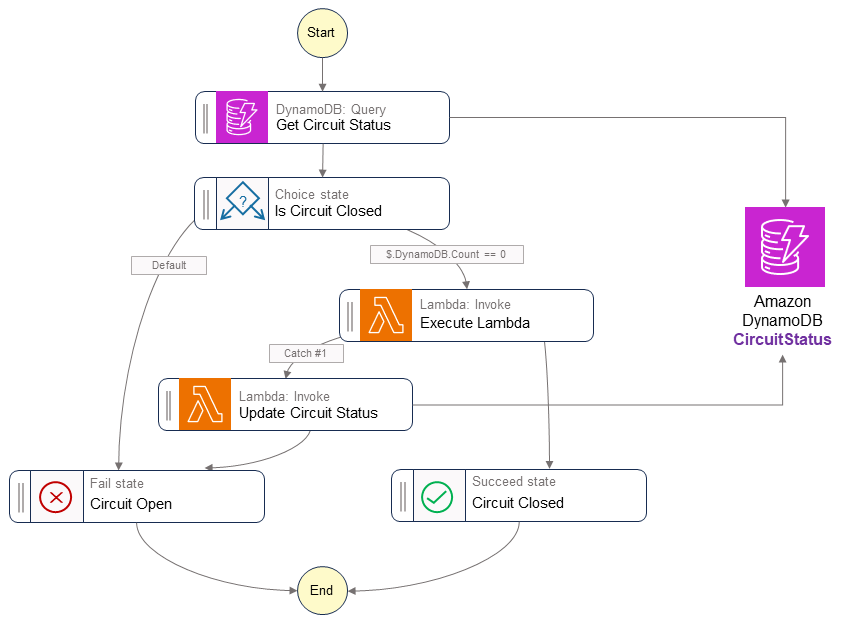
サービス呼び出しが失敗またはタイムアウトになった場合、アプリケーションは定義された回数だけエクスポネンシャルバックオフを使って再試行をおこないます。再試行後にサービス呼び出しが失敗した場合、ワークフローはサービスのCircuitStatusテーブルにレコードをExpiryTimeStampと一緒に挿入し、ワークフローはFAIL状態で終了します。サーキットブレーカーが開いている限り、同じサービスへの後続の呼び出しは即座に失敗を返します。ステートマシン定義のGet Circuit Statusステップは、ExpiryTimeStamp値に基づいてサービスの可用性を確認します。期限切れのアイテムはDynamoDBのtime to live(TTL)機能を使用してCircuitStatusテーブルから削除されます。
サンプルコード
以下のコードはLambda関数GetCircuitStatusを使って、サーキットブレーカーステータスを確認しています。
var serviceDetails = _dbContext.QueryAsync<CircuitBreaker>(serviceName, QueryOperator.GreaterThan, new List<object> {currentTimeStamp}).GetRemainingAsync(); if (serviceDetails.Result.Count > 0) { functionData.CircuitStatus = serviceDetails.Result[0].CircuitStatus; } else { functionData.CircuitStatus = ""; }
以下のコードでは、Step FunctionsワークフローでのAmazon ステートメント言語での定義を示しています。
"Is Circuit Closed": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.CircuitStatus",
"StringEquals": "OPEN",
"Next": "Circuit Open"
},
{
"Variable": "$.CircuitStatus",
"StringEquals": "",
"Next": "Execute Lambda"
}
]
},
"Circuit Open": {
"Type": "Fail"
}
GitHubリポジトリ
このパターンのサンプルアーキテクチャの実装全体は、GitHubリポジトリ https://github.com/aws-samples/circuit-breaker-netcore-blog をご確認ください。
参考ブログ
関連するコンテンツ
イベントソーシングパターン(Event sourcing pattern)
意図
イベント駆動アーキテクチャでは、イベントソーシングパターンが状態の変化をもたらすイベントをデータストアに格納します。これにより状態変更の完全な履歴をキャプチャして維持することができ、監査可能性、トレーサビリティおよび過去の状態の分析が向上します。
動機
複数のマイクロサービスが協調してリクエストを処理し、イベントを介してコミュニケーションをおこないます。これらのイベントは状態(データ)の変更となります。イベントオブジェクトを発生した順序で格納することは、データエンティティの現在の状態に関する重要な情報とその状態にどのような経緯で至ったのかを示す追加情報を提供します。
適用
次のときにイベントソーシングパターンを適用します:
- トラッキングのためにアプリケーションで発生したイベントの不変の履歴が必要なとき
- 信頼できる唯一の情報源(SSOT)からの多角的なデータ予測が必要なとき
- アプリケーションの状態をポイントインタイムでの再構築する必要なとき
- アプリケーション状態の長期保存は必要ないが、必要に応じて再構築したいとき
- ワークロードの読み取り量と書き込み量は異なるとき。例えば、リアルタイム処理を必要としない書き込み集中型のワークロードがあるとき。
- アプリケーションのパフォーマンスやその他のメトリクスを分析するために変更データキャプチャ(CDC)が必要なとき
- 報告とコンプライアンスのために、システムで発生したすべてのイベントに対する監査データが必要なとき
- 可能性のある最終状態を判断するため、リプレイプロセス中の変更(新規作成、更新、削除)イベントによるしてwhat-ifシナリオを引き出したいとき
問題と注意事項
- 楽観的同時実行制御:このパターンは、システムの状態変化を引き起こす全イベントを保存します。複数のユーザーやサービスが同時に同じデータを更新しようとすると、イベントの衝突が発生します。このような衝突は、競合するイベントが同時に作成・適用されることで発生し、その結果として最終的なデータ状態が現実と一致しなくなります。この問題を解決するには、イベントの衝突を検出して解決するストラテジーを実装します。例えば、バージョニングを含めたり、イベントにタイムスタンプを追加して更新銃所を追跡したりすることで、楽観的な同時実行制御スキームを実装することができます。
- 複雑さ:イベントソーシングを実装するには、従来のCRUD操作からイベント駆動思考への転換が必須です。システムを元の状態に復元するために使用されるリプレイプロセスは、データの冪等性を保証するために複雑になる可能性があります。イベントストレージ、バックアップ、スナップショットも複雑さを増す可能性があります。
- 結果整合性:コマンドクエリ責任分離(CQRS)パターンやマテリアライズドビューを使用してデータを更新するとレイテンシが発生するため、イベントから派生したデータプロジェクションは結果整合性がなくなります。コンシューマがイベントストアからデータを処理し、パブリッシャーが新しいデータを送信すると、データプロジェクションやアプリケーションオブジェクトが現在の状態を表していない可能性があります。
- クエリ:イベントログから現在または集計データを取得することは、特に複雑なクエリやレポーティングタスクの場合、従来のデータベースと比較してより複雑で遅延する可能性があります。この問題を軽減するために、イベントソーシングはしばしばCQRSパターンで実装されます。
- イベントストアのサイズとコスト:イベントが継続的に永続化されるにつれ、特にイベントスループットが高いシステムや保持期間が長いシステムでは、イベントストアのサイズが指数関数的に増大する可能性があります。そのため、イベントストアが大きくなりすぎないように、定期的にイベントデータをコスト効率の良いストレージにアーカイブする必要があります。
- イベントストアのスケーラビリティ:イベントストアは、大量の書き込みと読み取りの両方を効率的に処理しなければなりません。イベントストアのスケーリングは困難であるため、シャードやパーティションを提供するデータストアを利用することが重要です。
- 効率と最適化:書き込みと読み取りの両方の操作を効率的に処理するイベントストアを選択または設計します。イベントストアは、アプリケーションで想定されるイベント量とクエリパターンに合わせて最適化するべきです。インデックスとクエリのメカニズムを実装することで、アプリケーションの状態を再構築する際にイベントの収集を高速化することができます。また、クエリ最適化機能を提供するイベントストア専用のデータベースやライブラリの使用も検討できます。
- スナップショット:時間ベースでの活性化によって、イベントログを定期的にバックアップするしなければなりません。最後にバックアップに成功したデータからイベントをリプレイすることで、アプリケーションの状態をポイントインタイムでリカバリすることができるべきです。目標復旧地点(RPO)とは、最後のデータ復旧地点からの許容可能な最大時間のことです。RPOは、最後のリカバリポイントからサービス中断までの間に許容できるデータ損失を定義します。データとイベントストアの毎日のスナップショットの頻度は、アプリケーションのRPOに基づく必要があります。
- 時刻センシティブ:イベントは発生した順に保存されます。したがって、ネットワークの信頼性はこのパターンを実装する際に考慮すべき重要な要素です。レイテンシの問題は、誤ったシステム状態につながる可能性があります。イベントをイベントストアに格納するためにat-most-onceデリバリー機能を有する先入れ先出し(FIFO)キューを利用します。
- イベントリプレイのパフォーマンス:現在のアプリケーションの状態を再構築するために、かなりの数のイベントをリプレイすることは、時間がかかる可能性があります。特にアーカイブされたデータからイベントをリプレイする場合は、パフォーマンスを向上させるための最適化が必要です。
- 外部システムの更新:イベントソーシングパターンを利用するアプリケーションは、外部システムのデータストアを更新する可能性があり、これらの更新をイベントオブジェクトとしてキャプチャする可能性があります。イベントのリプレイ中に、外部システムが更新を予期していない場合、問題になることがあります。このような場合、外部システムの更新を制御するために機能フラグを使います。
- 外部システムクエリ:外部システム呼び出しが呼び出しの日時にセンシティブな場合、受信したデータを内部データストアに保存して、リプレイに使用することができます。
- イベントのバージョン管理:アプリケーションの進化に伴い、イベントの構造(スキーマ)が変化する可能性があります。後方互換性と前方互換性を確保するために、イベントのバージョニング戦略を実装することが必要です。これには、イベントペイロードにバージョンフィールドを含めることや、リプレイ時に異なるイベントバージョンを適切に処理することが含まれます。
実装
高レベルアーキテクチャ
コマンドとイベント
分散イベント駆動マイクロサービスアプリケーションでは、コマンドはサービスに送信される指示やリクエストを表し、通常はその状態の変更を開始することを意図しています。サービスはこれらのコマンドを処理し、コマンドの正当性と現在の状態への適用性を評価します。コマンドが正常に実行された場合、サービスは実行されたアクションと関連する状態情報を示すイベントを発行することによって応答します。たとえば次の図では、bookingサービスはRide bookedイベントを発することによってBook rideコマンドに応答します。
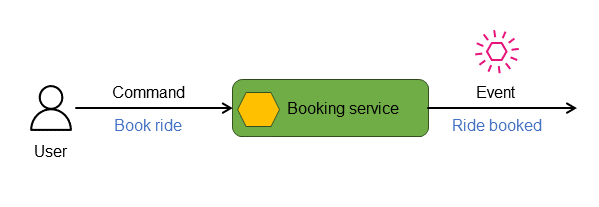
イベントストア
イベントは、イベントストアとして知られる不変で追記可能な時系列に並べられたリポジトリまたはデータストアに記録されます。各状態の変更は、個別のイベント・オブジェクトとして扱われます。既知の初期状態、現在の状態および任意のpoint-in-timeビューを持つエンティティオブジェクトまたはデータストアは、イベントを発生順にリプレイすることで再構築できます。
イベントストアは、すべてのアクションと状態変化の履歴として機能し、貴重な信頼できる唯一の情報源として機能します。イベントストアを利用してリプレイプロセッサにイベントを渡すことで、システムの最終的な最新の状態を導き出せます。また、イベントストアを利用してリプレイプロセッサでイベントをリプレイすることにより、状態のpoint-in-timeビューを生成できます。イベントソーシングパターンでは、最新のイベントオブジェクトによって現在の状態が完全に表現されるとは限りません。現在の状態は、次の3つの方法のいずれかで導き出せます:
- 関連イベントを集約する。関連するイベントオブジェクトが組み合わされ、クエリ向けの現在の状態が生成されます。このアプローチは、イベントが結合されて読み取り専用のデータストアに書き込まれるという点でCQRSパターンと併用されることが多いです。
- マテリアライズドビューを使用する。マテリアライズドビューパターンでイベントソーシングを使用するとイベントデータを計算または要約し、関連するデータの現在の状態を取得することができます。
- イベントをリプレイする。イベントオブジェクトをリプレイして、現在の状態を生成するためのアクションを実行できます。
以下の図は、Ride bookedイベントがイベントストアに格納される様子を示します。
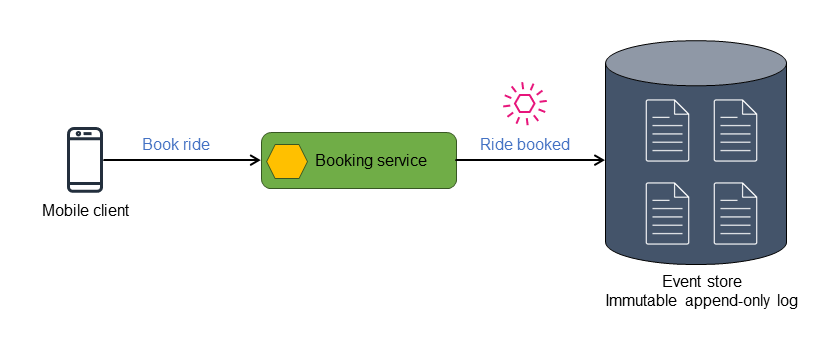
イベントストアは格納するイベントを発行し、そのイベントがフィルタリングされ、後続のアクションのために適切なプロセッサにルーティングすることができます。例えばイベントは状態を要約し、マテリアライズドビューを表示するビュープロセッサにルーティングすることができます。イベントは対象のデータストアのデータ形式に変換されます。このアーキテクチャは、異なるタイプのデータストアを派生させるために拡張することができ、データのポリグロット永続化につながります。
以下の図では、乗車予約アプリケーションのイベントを説明しています。アプリケーション内で発生するすべてのイベントは、イベントストアに格納されます。格納されたイベントは、フィルターされ、異なるコンシューマにルーティングされます。
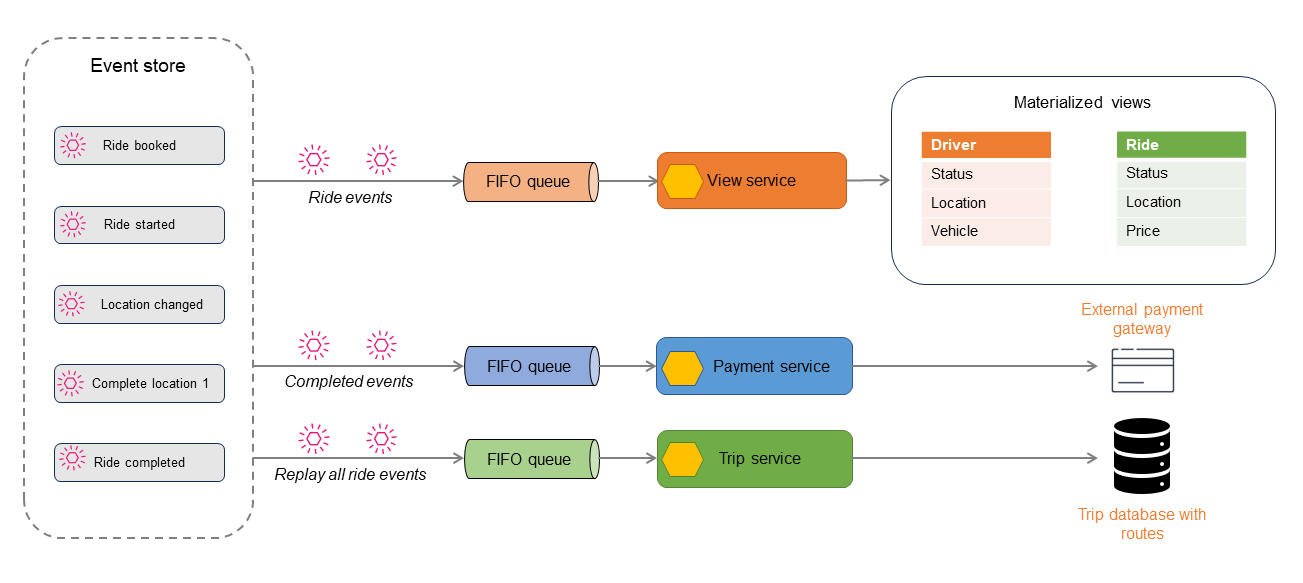
Rideイベントは、CQRSまたはマテリアライズドビューパターンを利用して読み取り専用のデータストアを生成するために使用できます。読み取り専用データストアをクエリすることでRide、DriverまたはBookingの現在の状態を取得できます。Location changedやRide completedなどの一部のイベントは、支払い処理のために別のコンシューマに発行されます。Rideが完了すると、全てのRideイベントがリプレイされて監査またはレポート目的で乗車履歴が作成されます。
イベントソーシングパターンは、point-in-timeリカバリを必要とするアプリケーションで頻繁に使用され、また信頼できる唯一の情報源を使用することにより、データを異なるフォーマットで投影する必要がある場合にも使用されます。これらの操作には、イベントを実行して必要な終了状態を導出するためのリプレイ処理が必要です。また、リプレイプロセッサは既知の開始ポイントを必要とする場合があります—理想的には、アプリケーションの起動からではありません、なぜなら効率的ではないためです。システム状態のスナップショットを定期的に取得し、より少ない数のイベントを適用して最新の状態を導出することを推奨します。
AWSサービスを利用した実装
以下のアーキテクチャでは、Amazon Kinesis Data Streamsをイベントストアとして使用しています。このサービスはアプリケーションの変更をイベントとしてキャプチャして管理し、高スループットとリアルタイムのデータストリーミングソリューションを提供します。AWS上でイベントソーシングパターンを実装するには、アプリケーションのニーズに応じてAmazon EventBridgeやAmazon Managed Streaming for Apache Kafka(Amazon MSK)などのサービスを利用することもできます。
耐久性を高め、監査を可能にするために、Kinesis Data StreamsによってキャプチャされたイベントをAmazon Simple Storage Service(Amazon S3)にアーカイブすることができます。このデュアルストレージアプローチは、将来の分析やコンプライアンスのために過去のイベントデータを安全に保持するのに役立ちます。
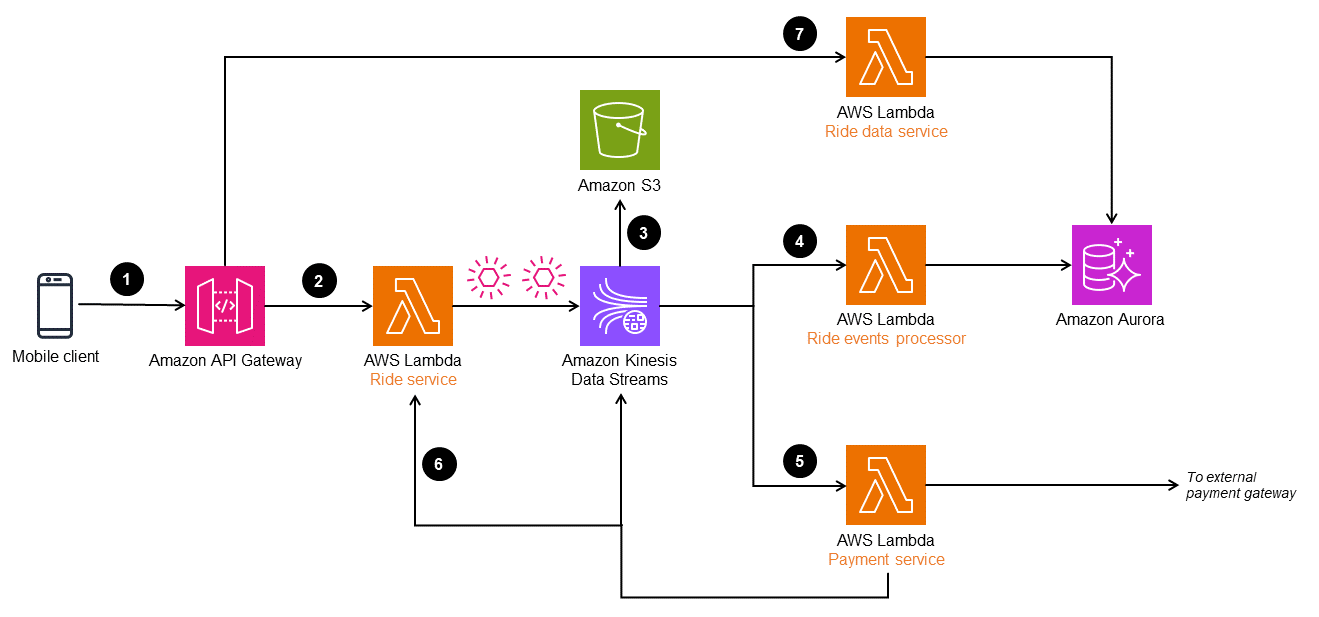
ワークフローは以下のステップで構成されます:
- モバイルクライアントからAmazon API Gatewayエンドポイントに乗車予約リクエストがおこなわれる
- Rideマイクロサービス(Lambda関数
Ride service)がリクエストを受け取り、オブジェクトを変換し、Kinesis Data Streamsにパブリッシュします - Kinesis Data Streamsのイベントデータは、コンプライアンスと監査履歴のためにAmazon S3に保存されます
- イベントはLambda関数
Ride event processorによって変換・処理され、Amazon Auroraデータベースに格納されて乗車データのマテリアライズドビューを提供します - 完了したRideイベントはフィルタリングされ、支払い処理のために外部の支払いゲートウェイに送信されます。支払いが完了すると、別のイベントがKinesis Data Streamsに送信され、Rideデータベースが更新されます
- 乗車が完了すると、RideイベントがLambda関数
Ride serviceでリプレイされ、行程と乗車の履歴が構築されます - 乗車情報は、Auroraデータベースから読み込む
Ride data serviceを通じて読み込むことができます
API GatewayはLambda関数Ride serviceを使わずに、イベントオブジェクトを直接Kinesis Data Streamsに送信することもできます。しかし、配車サービスのような複雑なシステムではイベントオブジェクトはデータストリームに取り込まれる前に処理され、エンリッチ化される必要があるかもしれない。このため、このアーキテクチャではKinesis Data Streamsに送信する前にイベントを処理するRideサービスを用意しています。
参考ブログ
パブリッシュ・サブスクライブパターン(Publish-subscribe pattern)
意図
パブリッシュ・サブスクライブのパターンはパブ・サブパターンとも呼ばれ、メッセージの送り手(パブリッシャー)と関心のある受け手(サブスクライバー)を切り離すメッセージングパターンです。このパターンは、メッセージブローカーやルーター(メッセージインフラストラクチャ)として知られる仲介者を介してメッセージやイベントを発行することで、非同期通信を実装します。パブリッシュ・サブスクライブパターンは、メッセージ配信の責任をメッセージインフラストラクチャにオフロードすることで、送信者のスケーラビリティと応答性を向上させます。
動機
分散アーキテクチャでは、システム内でイベントが発生するとシステムコンポーネントは他のコンポーネントに情報を提供する必要があります。パブリッシュ・サブスクライブパターンは、メッセージインフラストラクチャがメッセージルーティングや信頼性のあるデリバリーといったコミュニケーションの責任を処理する一方で、アプリケーションがコア機能に集中できるように関心事を分離します。パブリッシュ・サブスクライブパターンは、パブリッシャーとサブスクライバーを分離する非同期メッセージングを可能にします。また、パブリッシャーはサブスクライバーを意識することなく、メッセージを送信することができます。
適用
パブリッシュ・サブスクライブパターンは次のときに利用されます:
- 1つのメッセージに異なるワークフローがあるとき、並列処理が必要になります
- 複数のサブスクライバーに対するブロードキャストやレシーバーからのリアルタイムでのレスポンスは必要ありません
- システムやアプリケーションはデータまたは状態の結果整合性を許容できます
- アプリケーションやコンポーネントは、異なる言語、プロトコル、プラットフォームを利用する他のアプリケーションやサービスと通信しなくてはなりません
問題と注意事項
- サブスクライバーの有無:パブリッシャーはサブスクライバーが聞いている 聞いていないかはわかりません。発行されたメッセージは本来一過性のものであり、サブスクライバーが利用可能でない場合には無視される可能性があります。
- メッセージ配信の保証:通常、パブリッシュ・サブスクライブパターンは全てのサブスクライバータイプに対してメッセージの配信を保証することはできませんが、Amazon Simple Notification Service(Amazon SNS)のような特定のサービスではサブスクライバーのサブセットに対して正確に一度だけメッセージを配信することができます
- Time to live(TTL):メッセージには生存期間と有効期限があり、その期間内に処理されないと失効します。公開されたメッセージをキューに追加することで、TTL期間を超えても生存して処理を保証することができます。
- メッセージの関連性:プロデューサーはメッセージデータの一部として関連する期間を設定することができ、この期間を過ぎるとメッセージを破棄することができます。メッセージの処理方法を決定する前に、この情報を調べるようにコンシューマを設計することを検討してください。
- 結果整合性:メッセージが発行されてからサブスクライバーによって処理されるまでに遅延があります。このため、強力な整合性が要求される場合にサブスクライバーのデータストアが結果整合性を失われる可能性があります。また、プロデューサーとコンシューマがほぼリアルタイムのやり取りを必要とする場合にも、結果整合性が問題になることがあります。
- 単方向通信:パブリッシュ・サブスクライブパターンは単方向のコミュニケーションです。リターンサブスクリプションチャネルを持つ双方向メッセージングを必要とするアプリケーションは、同期的応答が必要とされる場合、リクエスト・リプライパターンの使用を検討すべきです。
- メッセージの順序:メッセージの順序は保証されていません。コンシューマが順序付きメッセージを必要とする場合、Amazon SNS FIFOトピックを使用して順序を保証することを推奨します。
- メッセージの重複:メッセージングインフラストラクチャに基づき、重複したメッセージがコンシューマに配信される可能性があります。コンシューマは重複メッセージ処理を制御するために、冪等性を確保するように設計されなければなりません。もしくは、Amazon SNSのFIFOトピックを使用して一度だけの配信を保証します。
- メッセージのフィルタリング:コンシューマは、プロデューサーが発行したメッセージの一部にしか関心がないことが多いです。トピックやコンテンツフィルターによってサブスクライバーが受信するメッセージをフィルタリングしたり限定したりできるようにする仕組みを提供しましょう。
- メッセージのリプレイ:メッセージリプレイ機能は、メッセージングインフラストラクチャに依存するでしょう。また、ユースケースに応じてカスタム実装を提供することができます。
- デッドレターキュー:郵便システムにおいてデッドレターオフィスは配達不能の郵便物を処理する施設です。パブ・サブメッセージングにおいてデッドレターキュー(DLQ)はサブスクライバーのエンドポイントに配送できないメッセージのためのキューです。
実装
高レベルアーキテクチャ
パブリッシュ・サブスクライブパターンでは、メッセージブローカーやルーターと呼ばれる非同期メッセージングサブシステムがサブスクリプションを追跡します。プロデューサーがイベントをパブリッシュすると、メッセージングインフラストラクチャは各コンシューマにメッセージを配信します。メッセージがサブスクライバーに配信された後、そのメッセージはメッセージインフラストラクチャから削除されます。メッセージブローカーやルーターは、イベントプロデューサーとメッセージコンシューマを次の方法で分離します:
- 定義済メッセージフォーマットを使用し、メッセージにパッケージされたイベントをプロデューサーが発行するための入力チャネルを提供します
- サブスクリプションごとに個別の出力チャネルを作成します。サブスクリプションはコンシューマのコネクションであり、コンシューマは特定の入力チャネルに関連付けられたイベントメッセージをリッスンします。
- イベントがパブリッシュされたとき、すべてのコンシューマのために入力チャネルから出力チャネルにメッセージをコピーします

AWSサービスを利用した実装
Amazon SNS
Amazon SNSは完全に管理されたパブリッシャー・サブスクライバーサービスで、分散アプリケーションを分離するためのアプリケーション間(A2A)メッセージングを提供します。また、SMS、電子メール、その他のプッシュ通知を送信するためのアプリケーション・個人間(A2P)メッセージングも提供します。
Amazon SNSは、標準と先入れ先出し(FIFO)の2種類のトピックを提供します。
- 標準トピックは1秒あたりのメッセージ数を無制限にサポートし、ベストエフォート順序付けと重複排除を提供します
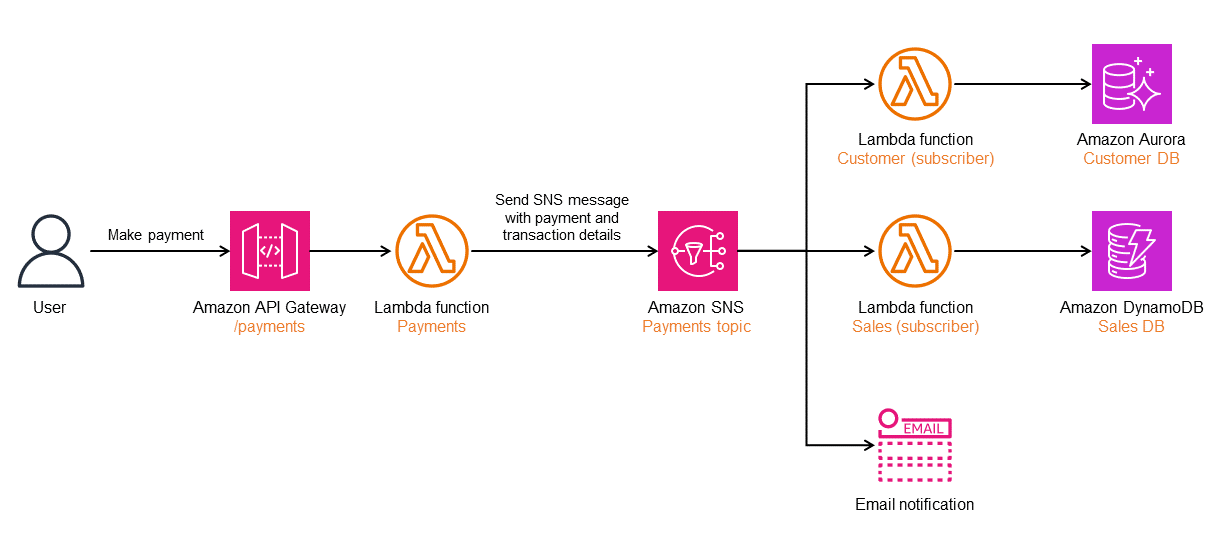
次の図は、Amazon SNSを使用したパブリッシュ・サブスクライブパターンの実装方法を示しています。ユーザーが支払いをおこなうと、Lambda関数PaymentsによってSNSメッセージがSNSトピックPaymentsに送信されます。このSNSトピックには3つのサブスクライバーがあります。各サブスクライバーはメッセージのコピーを受信し、それを処理します。
Amazon EventBridge
複数のプロデューサーから異なるプロトコルを介してサブスクライブしているコンシューマ、ダイレクトサブスクリプションやファンアウトサブスクリプションのより複雑なメッセージのルーティングが必要な場合、Amazon EventBridgeを利用できます。また、EventBridgeはコンテンツベースのルーティング、フィルタリング、シーケンスおよび分割または集約もサポートしています。次の図では、イベントルールを使用してサブスクライバーを定義するパブリッシュ・サブスクライブパターンのバージョンを構築するためにEventBridgeが利用されています。ユーザーが支払いをおこなった後、Lambda関数Paymentsは異なるターゲットを指す3つのルールを持つカスタムスキーマに基づいて、デフォルトのイベントバスを使用してEventBridgeにメッセージを送信する。各マイクロサービスはメッセージを処理し、必要なアクションを実行します。

ワークショップ
- Building event-driven architectures on AWS
- Send Fanout Event Notifications with Amazon Simple Queue Service (Amazon SQS) and Amazon Simple Notification Service (Amazon SNS)
参考ブログ
- Choosing between messaging services for serverless applications
- Designing durable serverless applications with DLQs for Amazon SNS, Amazon SQS, AWS Lambda
- Simplify your pub/sub messaging with Amazon SNS message filtering
関連するコンテンツ
バックオフを伴う再試行パターン(Retry with backoff pattern)
意図
バックオフを伴う再試行パターンは、一過的なエラーによって失敗した操作を透過的に再試行することでアプリケーションの安定性を向上させます。
動機
分散アーキテクチャにおいて、一時的なエラーはサービスのスロットリング、ネットワーク接続の一時的な喪失または一時的なサービス利用不可状態によって引き起こされる可能性があります。このような一過性のエラーによって失敗した操作を自動的に再試行することで、ユーザーエクスペリエンスとアプリケーションの回復力が向上します。しかし、頻繁な再試行はネットワーク帯域幅に負荷をかけ、競合を引き起こす可能性があります。エクスポネンシャルバックオフは、指定された再試行回数の待ち時間を増やすことで操作を再試行する手法です。
適用
バックオフを伴う再試行パターンは次のようなときに適用されます:
- サービスが過負荷を防ぐためにリクエストを頻繁にスロットルし、呼び出し処理で例外429 Too many requestsが発生しているとき
- ネットワークは分散アーキテクチャでは見えない参加者であり、一時的なネットワークの問題は障害を引き起こしているとき
- 呼び出されるサービスが一時的に利用できなくなり、障害原因となるとき。このパターンを使用してバックオフタイムアウトを導入しない限り、頻繁な再試行はサービ スの劣化を引き起こす可能性があります。
問題と注意事項
- 冪等性:メソッドに対する複数の呼び出しがシステム状態に対する1回の呼び出しと同じ作用となる場合、その操作は冪等であるとみなされます。バックオフを伴う再試行パターンを利用する場合、操作は冪等であるべきです。そうでないと、部分的な更新によってシステム状態が破損する可能性があります。
- ネットワーク帯域幅:過大な再試行がネットワーク帯域幅を占有して応答時間が遅くなると、サービスが劣化することがあります
- フェイルファストシナリオ:非一過性のエラーについて障害の原因を特定できるのであれば、サーキットブレーカーパターンを利用して即座に失敗とする方が効率的です。
- バックオフレート:指数関数的なバックオフを導入すると、サービスのタイムアウトに影響し、エンドユーザーの待ち時間が長くなる可能性があります
実装
高レベルアーキテクチャ
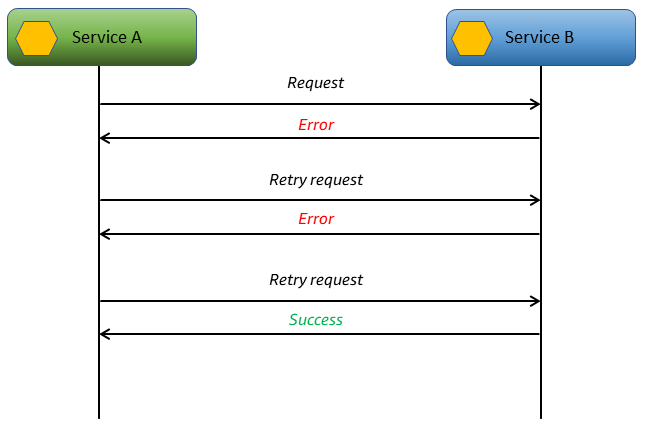
次の図は、サービスAからサービスBへの呼び出しに成功レスポンスが返されるまで再試行する方法を示しています。数回試してもサービスBが成功レスポンスを返さない場合、サービスAは再試行を中止して呼び出し元に失敗を返すことができます。
AWSサービスを利用した実装
次の図は、カスタマーサポートプラットフォームにおけるチケット処理のワークフローを示しています。不満のある顧客からのチケットは、チケットの優先度を自動的にエスカレーションすることですぐに処理されます。Lambda関数Ticket infoはチケットの詳細を抽出し、Lambda関数Get sentimentを呼び出します。Lambda関数Get sentimentはAmazon Comprehendhttp://aws.amazon.com/comprehend/(図示せず)にチケット詳細情報を渡すことで顧客の感情をチェックします。
Lambda関数Get sentimentの呼び出しに失敗した場合、ワークフローは操作を3回再試行します。AWS Step Functionsでは、バックオフ値を設定することでエクスポネンシャルバックオフを利用できます。
この例では、1.5秒の増加乗数で最大3回のリトライが設定されています。最初のリトライが3秒後に実行された場合、2回目のリトライは3 x 1.5秒 = 4.5秒後に、3回目のリトライは4.5 x 1.5秒 = 6.75秒後に実行されます。3回目のリトライが失敗すると、ワークフローは失敗となります。バックオフロジックはカスタムコードを必要としません―AWS Step Functionsによって設定として提供されます。

サンプルコード
次のコードは、バックオフを伴う再試行パターンの実装です。
public async Task DoRetriesWithBackOff() { int retries = 0; bool retry; do { //Sample object for sending parameters var parameterObj = new InputParameter { SimulateTimeout = "false" }; var content = new StringContent(JsonConvert.SerializeObject(parameterObj), System.Text.Encoding.UTF8, "application/json"); var waitInMilliseconds = Convert.ToInt32((Math.Pow(2, retries) - 1) * 100); System.Threading.Thread.Sleep(waitInMilliseconds); var response = await _client.PostAsync(_baseURL, content); switch (response.StatusCode) { //Success case HttpStatusCode.OK: retry = false; Console.WriteLine(response.Content.ReadAsStringAsync().Result); break; //Throttling, timeouts case HttpStatusCode.TooManyRequests: case HttpStatusCode.GatewayTimeout: retry = true; break; //Some other error occured, so stop calling the API default: retry = false; break; } retries++; } while (retry && retries < MAX_RETRIES); }
GitHubリポジトリ
このパターンのサンプルアーキテクチャの実装全体は、GitHubリポジトリ https://github.com/aws-samples/retry-with-backoff をご確認ください。
関連するコンテンツ
- Timeouts, retries, and backoff with jitter (Amazon Builders' Library)
Sagaパターン
サーガは一連のローカルトランザクションから構成されます。サーガ内の各ローカルトランザクションはデータベースを更新し、次のローカルトランザクションをトリガーします。トランザクションが失敗した場合、サーガは補正トランザクションを実行し、前のトランザクションでのデータベース変更を元に戻します。
この一連のローカルトランザクションは継続原則と補正原則を利用することで、ビジネスワークフローを実現するのに役立ちます。継続原則はワークフローの前方回復を決定し、補正原則は後方回復を決定します。トランザクションのいずれかのステップで更新が失敗した場合、サーガは継続(トランザクションの再試行)または補正(前のデータ状態に戻る)のためのイベントを発行します。これによってデータの完全性が維持され、データストア間で整合性が保たれる。
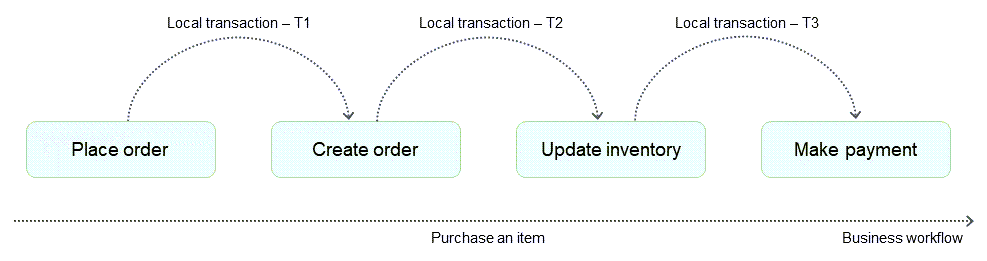
例えば、ユーザーがオンライン小売業者から書籍を購入する場合、そのプロセスは注文の作成、在庫の更新、支払い、発送といった一連のトランザクションで構成され、ビジネスワークフローを表しています。ワークフローを完了させるため、分散アーキテクチャは、注文データベースに注文を作成し、在庫データベースを更新し、支払いデータベースを更新する一連のローカルトランザクションを発行します。以下の図が示すように、処理が成功するとこれらのトランザクションが順次呼び出されてビジネスワークフローが完了します。しかし、これらのローカルトランザクションのいずれかが失敗した場合、システムは適切な次のステップ—すなわちフ前方回復または後方回復のいずれかを決定できる必要があります。
次の2つのシナリオは、次のステップが前方回復なのか後方回復なのかを判断するのに役立ちます:
- プラットフォームレベルの障害、インフラストラクチャに何らかの問題が発生し、トランザクションが失敗した場合。この場合、Sagaパターンはローカルトランザクションを再試行し、ビジネスプロセスを継続することで前方回復を実行できます。
- アプリケーションレベルの障害、無効な支払いが原因で決済サービスが失敗した場合。この場合、Sagaパターンは在庫データベースと注文データベースを更新し、以前の状態に戻す補正トランザクションを発行することによって後方回復を実行できます。
Sagaパターンはビジネスワークフローを制御し、前方回復によって望ましい最終状態に到達させます。障害が発生した場合、データ整合性の問題を回避するために後方回復を使用してローカルトランザクションを元に戻します。
Sagaパターンには、コレオグラフィとオーケストレーションという2つのバリエーションがあります。
Sagaコレオグラフィ
Sagaコレオグラフィパターンはマイクロサービスによって発行されたイベントに依存します。サーガの参加者(マイクロサービス)はイベントをサブスクライブし、イベントトリガーに基づいて動作します。例えば、以下の図のorderサービスはイベントOrderPlacedを発行します。inventoryサービスはイベントをサブスクライブし、イベントOrderPlacedを発行するときにインベントリを更新します。同様に、参加者サービスは発行されたイベントのコンテキストに基づいて動作します。
Sagaコレオグラフィパターンは、サーガの参加者が少数で単一障害点のないシンプルな実装が必要な場合に適しています。参加者が増えると、このパターンを使って参加者間の依存関係を追跡することが難しくなります。

詳細は本ガイドのSagaコレオグラフィのセクションをご覧ください。
Sagaオーケストレーション
Sagaオーケストレーションパターンには、オーケストレータと呼ばれる中央調整役がいます。オーケストレータはトランザクションのライフサイクル全体を管理・調整します。オーケストレータは、トランザクションを完了するために実行される一連のステップを把握しています。ステップを実行するために、参加者マイクロサービスにメッセージを送り、処理を実行させます。参加者マイクロサービスは操作を完了し、オーケストレータにメッセージを送り返します。受け取ったメッセージに基づいて、オーケストレータはトランザクションで次に実行するマイクロサービスを決定します。
Sagaオーケストレーションパターンは、参加者が多く、サーガ参加者間の疎結合が必要な場合に適しています。オーケストレータは、参加者を疎結合にすることで、ロジックの複雑さをカプセル化します。しかし、オーケストレータはワークフロー全体を制御するため、単一障害点となる可能性があります。
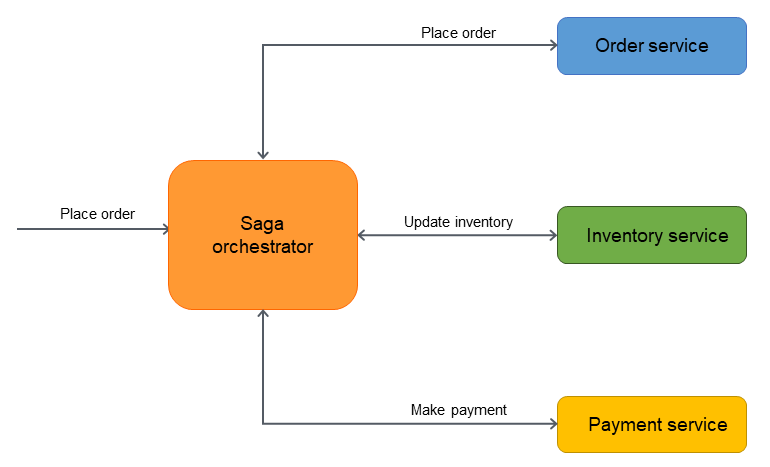
詳細は本ガイドのSagaオーケストレーションのセクションをご覧ください。
Sagaコレオグラフィパターン(Saga choreography pattern)
意図
Sagaコレオグラフィパターンは、イベントサブスクリプションを使用することで、複数のサービスにまたがる分散トランザクションにおいてデータ完全性を維持するのに役立ちます。分散トランザクションでは、トランザクションが完了する前に複数のサービスが呼び出される可能性があります。サービスが異なるデータストアにデータを格納する場合、これらのデータストア間でデータ整合性を維持することは困難な場合があります。
動機
トランザクションとは複数のステップを含んだ1つの作業単位であり、すべてのステップが完全に実行されるかどのステップも実行されず、結果として整合性のあるデータストアが得られます。Atomicity(原子性)、Consistency(一貫性)、Isolation(独立性)、Durability(永続性)(ACID)という用語は、トランザクションの特性を定義しています。リレーショナルデータベースはデータ整合性を維持するためにACIDトランザクションを提供しています。
トランザクションの整合性を維持するため、リレーショナルデータベースは2相コミット(2PC)方式を採用しています。これは準備フェーズとコミットフェーズから構成されます。
- 準備フェーズでは、調整プロセスがトランザクションの参加プロセス(参加者)に対してトランザクションをコミットするかロールバックするかを約束するよう要求します。
- コミットフェーズでは、調整プロセスが参加者にトランザクションをコミットするように要求します。準備フェーズで参加者がコミットに合意できない場合、トランザク ションはロールバックされます。
データベース・パー・サービス設計パターンに従う分散システムでは、2相コミットは選択できません。なぜなら、各トランザクションは様々なデータベースに分散しており、リレーショナルデータストアにおける2相コミットと同様のプロセスを調整できる単一のコントローラが存在しないからです。この場合の解決策のひとつがSagaコレオグラフィパターンを採用することです。
適用
Sagaコレオグラフィパターンは以下のような場合に採用します:
- 複数のデータストアにまたがる分散トランザクションにおいて、システムがデータの完全性と整合性を必要とする場合
- データストア(例えばNoSQLデータベース)がACIDトランザクションを提供する2相コミット機能を有しておらず、単一のトランザクション内で複数テーブルを更新する必要があり、アプリケーション境界内で2相コミットを実装するのは複雑な作業になる場合
- 参加者のトランザクションを管理する中央制御プロセスが単一障害点となる可能性がある場合
- サーガの参加者は独立したサービスであり、疎結合にする必要がある場合
- ビジネスドメインにおいて境界コンテキスト同士でコミュニケーションを取る場合
問題と注意事項
- 複雑さ:マイクロサービスの数が増加するとマイクロサービス間の相互作用数が増加するため、Sagaコレオグラフィの管理が困難になる可能性があります。さらに、補正トランザクションと再試行がアプリケーションコードに複雑さを増加させ、メンテナンスのオーバーヘッドになる可能性があります。コレオグラフィはサーガの参加者が少数で、単一障害点のないシンプルな実装が必要な場合に適しています。参加者が増えると、このパターンを使って参加者間の依存関係を追跡するのが難しくなります。
- 回復力のある実装:Sagaコレオグラフィでは、タイムアウト、再試行その他のレジリエンシーパターンをグローバルに実装することは、Sagaオーケストレーションに比べて難しいです。コレオグラフィではオーケストレータレベルではなく、個々のコンポーネントで実装する必要があります。
- 循環依存関係:参加者は、互いに発行されたメッセージを処理します。結果として、循環依存関係が発生し、コードの複雑化やメンテナンスのオーバーヘッド、デッドロックの可能性があります。
- 二重書き込みの問題:マイクロサービスはアトミックにデータベースを更新し、イベントを発行する必要があります。どちらかの操作に失敗すると、整合性がとれない可能性があります。これを解決する方法の1つは、トランザクショナルアウトボックスパターンを採用することです。
- イベントを永続化する:サーガの参加者は発行されたイベントに基づいて動作します。監査、デバッグ、リプレイの目的でイベントを発生順に保存することは重要です。データ整合性を復元するためにシステム状態のリプレイが必要になった場合のために、イベントソーシングパターンを採用してイベントをイベントストアに永続化できます。また、イベントストアはシステムのすべての変更を反映するため、監査やトラブルシューティングに活用できます。
- 結果整合性:ローカルトランザクションの逐次処理によって結果整合性が得られますが、これは強い整合性を必要とするシステムでは問題となります。この問題は、整合性モデルに対するビジネスチームの期待値を設定するか、ユースケースを再検討して強い整合性を提供するデータベースに切り替えることで対処できます。
- 冪等性:予期しないクラッシュやオーケストレータの障害による一過性の障害が発生した場合に再実行ができるようにするため、サーガの参加者には冪等性が要求されます。
- トランザクションの独立性:Sagaパターンでは、ACIDトランザクションにおける4つの特性の1つであるトランザクション独立性が失われます。トランザクションの独立性の度合いは、他の並行トランザクションがそのトランザクションが操作するデータにどれだけ影響を与えることができるかを定義します。トランザクションの同時実行はデータの陳腐化につながる可能性があります。そのようなシナリオに対処するためにセマンティックロックの利用を推奨します。
- 観測可能性:観測可能性とは、実装とオーケストレーションプロセスにおける問題をトラブルシューティングするための詳細なロギングとトレースの実行のことです。サーガ参加者の数が増加し、デバッグが複雑になる場合に重要です。エンドツーエンドのモニタリングとレポーティングは、Sagaオーケストレーションと比較してSagaコレオグラフィではより困難です。
- レイテンシの問題:補正トランザクションはサーガが複数のステップで構成されている場合、全体のレスポンス時間にレイテンシを追加する可能性があります。トランザクションが同期的呼び出しをおこなう場合、レイテンシがさらに長くなる可能性があります。
実装
高レベルアーキテクチャ
以下のアーキテクチャ図において、Sagaコレオグラフィには3者の参加者が存在します:Orderサービス、Inventoryサービス、Paymentサービス。トランザクションを完了するには3つのステップが必要です:T1、T2、T3です。3つの補正トランザクションがデータを初期状態に戻します:C1、C2、C3です。
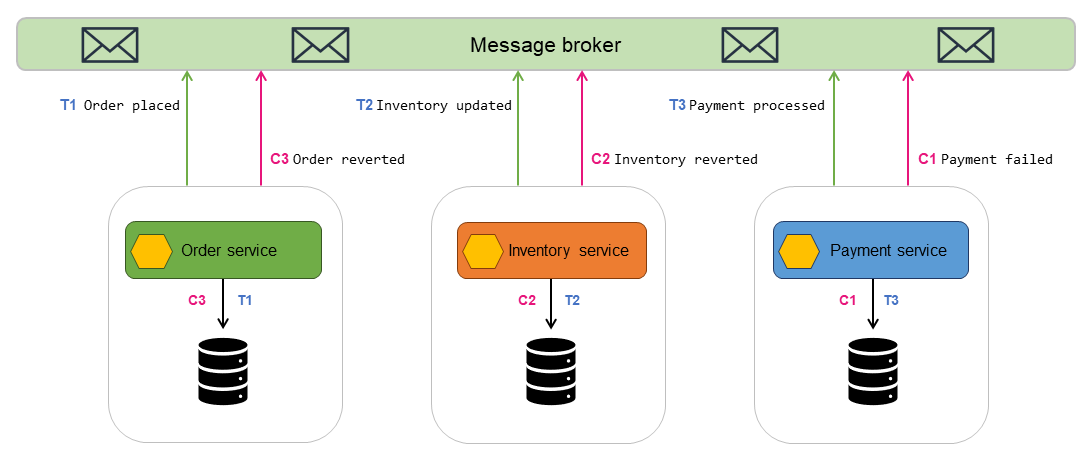
- OrderサービスがローカルトランザクションT1を実行し、アトミックにデータベースを更新し、メッセージ
Order placedをメッセージブローカーに発行します - InventoryサービスはOrderサービスのメッセージをサブスクライブしており、注文が作成されたというメッセージを受信します
- InvantoryサービスがローカルトランザクションT2を実行し、アトミックにデータベースを更新し、メッセージ
Inventory updatedをメッセージブローカーに発行します。 - PaymentサービスはInventoryサービスのメッセージをサブスクライブしており、在庫が更新されたというメッセージを受信します
- PaymentサービスがローカルトランザクションT3を実行し、支払い詳細についてデータベースをアトミックに更新し、メッセージ
Payment processedをメッセージブローカーに発行します - 決済が失敗した場合、Paymentサービスは補正トランザクションC1を実行し、アトミックにデータベース内の決済を元に戻し、メッセージブローカーにメッセージ
Payment failedを発行します - 補正トランザクションC2とC1は、データ整合性を復元するために実行されます
AWSサービスを利用した実装
Amazon EventBridgeを使うことで、Sagaコレオグラフィーパターンを実装できます。EventBridgeはイベントを使ってアプリケーションコンポーネントを接続します。イベントバスやパイプを通してイベントを処理します。イベントバスはイベントを受信し、ゼロ個以上の宛先(ターゲット)にイベントを配信するルーターです。イベントバスに関連するルールは受信したイベントを評価し、処理のためにターゲットにイベントを送信します。
以下のアーキテクチャでは:
- マイクロサービス—Orderサービス、Inventoryサービス、Paymentサービス—はLambda関数として実装されています
- 3つのカスタムEventBridgeバスが存在します:イベントバス
Orders、イベントバスInventory、イベントバスPayment - ルール
Orders、ルールInventory、ルールPaymentは対応するイベントバスに送信されるイベントにマッチし、Lambda関数を呼び出します

成功したシナリオでは、注文が発注されたとき:
- Orderサービスはリクエストを処理し、イベントバス
Ordersにイベントを送信します - ルール
Ordersがイベントにマッチし、Inventoryサービスを開始します - Inventoryサービスは在庫を更新し、イベントバス
Inventoryにイベントを送信します - ルール
Inventoryがイベントにマッチし、Paymentサービスを開始します - Paymentサービスは支払いを処理し、イベントバス
Paymentにイベントを送信します - ルール
Paymentがイベントにマッチし、イベント通知Payment processedをリスナーに送信します。 あるいは注文処理に問題がある場合、EventBridgeルールはデータの整合性と完全性を維持するためにデータ更新を戻す補正トランザクションを開始します - 支払いが失敗した場合、ルール
Paymentはイベントを処理してInventoryサービスを開始します。Inventoryサービスは、インベントリを元に戻すために補正トランザクションを開始します - 在庫が戻されると、Inventoryサービスはイベント
Inventory revertedをイベントバスInventoryに送信します。このイベントはルールInventoryによって処理されます。このイベントはOrderサービスを開始し、注文を削除するための補正トランザクションを開始します。
関連するコンテンツ
Sagaオーケストレーションパターン(Saga orchestration pattern)
意図
Sagaオーケストレーションパターンは、中央のコーディネータ(オーケストレータ)を使って複数のサービスにまたがる分散トランザクションでデータの整合性を保つために役立ちます。分散トランザクションでは、トランザクションが完了する前に複数のサービスが呼び出される可能性があります。サービスが異なるデータストアにデータを格納する場合、これらのデータストア間でデータの整合性を維持することが困難な場合があります。
動機
トランザクションとは複数のステップを含んだ1つの作業単位であり、すべてのステップが完全に実行されるかどのステップも実行されず、結果として整合性のあるデータストアが得られます。Atomicity(原子性)、Consistency(一貫性)、Isolation(独立性)、Durability(永続性)(ACID)という用語は、トランザクションの特性を定義しています。リレーショナルデータベースはデータ整合性を維持するためにACIDトランザクションを提供しています。
トランザクションの整合性を維持するため、リレーショナルデータベースは2相コミット(2PC)方式を採用しています。これは準備フェーズとコミットフェーズから構成されます。
- 準備フェーズでは、調整プロセスがトランザクションの参加プロセス(参加者)に対してトランザクションをコミットするかロールバックするかを約束するよう要求します。
- コミットフェーズでは、調整プロセスが参加者にトランザクションをコミットするように要求します。準備フェーズで参加者がコミットに合意できない場合、トランザク ションはロールバックされます。
データベース・パー・サービス設計パターンに従う分散システムでは、2相コミットは選択できません。なぜなら、各トランザクションは様々なデータベースに分散しており、リレーショナルデータストアにおける2相コミットと同様のプロセスを調整できる単一のコントローラが存在しないからです。この場合の解決策のひとつがSagaオーケストレーションパターンを採用することです。
適用
Sagaオーケストレーションパターンは以下のような場合に採用します:
- 複数のデータストアにまたがる分散トランザクションにおいて、システムがデータの完全性と整合性を必要とする場合
- データストアがACIDトランザクションを提供する2相コミット機能を有しておらず、アプリケーション境界内で2相コミットを実装するのは複雑な作業になる場合
- ACIDトランザクションを提供しないNoSQLデータベースがあり、単一トランザクション内で複数のテーブルを更新する必要がある場合
問題と注意事項
- 複雑さ:補正トランザクションと再試行がアプリケーションコードに複雑さを増加させ、メンテナンスのオーバーヘッドになる可能性があります。
- 結果整合性:ローカルトランザクションの逐次処理によって結果整合性が得られますが、これは強い整合性を必要とするシステムでは問題となります。この問題は、整合性モデルに対するビジネスチームの期待値を設定するか、ユースケースを再検討して強い整合性を提供するデータベースに切り替えることで対処できます。
- 冪等性:予期しないクラッシュやオーケストレータの障害による一過性の障害が発生した場合に再実行ができるようにするため、サーガの参加者には冪等性が要求されます。
- トランザクションの独立性:Sagaパターンではトランザクション独立性が失われます。トランザクションの同時実行はデータの陳腐化につながる可能性があります。そのようなシナリオに対処するためにセマンティックロックの利用を推奨します。
- 観測可能性:観測可能性とは、実装とオーケストレーションプロセスにおける問題をトラブルシューティングするための詳細なロギングとトレースの実行のことです。サーガ参加者の数が増加し、デバッグが複雑になる場合に重要です。
- レイテンシの問題:補正トランザクションはサーガが複数のステップで構成されている場合、全体のレスポンス時間にレイテンシを追加する可能性があります。この場合には同期的呼び出しを避けます。
- 単一障害点:オーケストレータはトランザクション全体を調整するため、単一障害点となる可能性があります。場合によっては、この問題のためにSagaコレオグラフィパターンが好ましいです。
実装
高レベルアーキテクチャ
以下のアーキテクチャ図において、Sagaコレオグラフィには3者の参加者が存在します:Orderサービス、Inventoryサービス、Paymentサービス。トランザクションを完了するには3つのステップが必要です:T1、T2、T3です。Sagaオーケストレータはステップとその実行順序を知っています。ステップT3が失敗した(支払いが失敗した)場合、オーケストレータは補正トランザクションC1、C2を実行し、初期状態にデータを戻します。
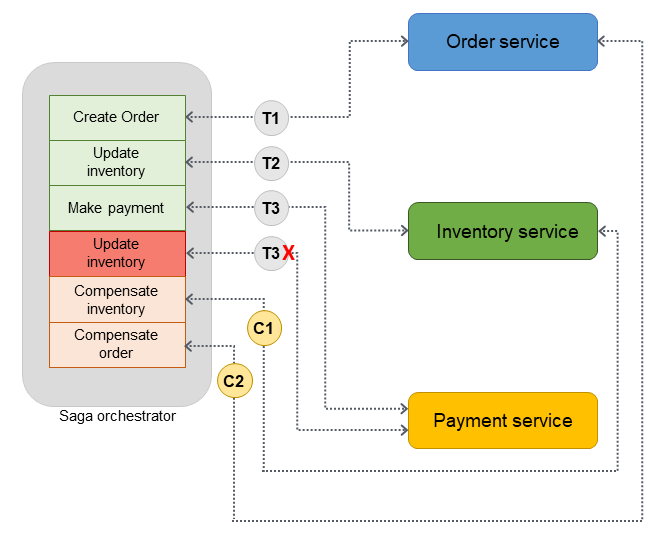
トランザクションが複数のデータベースに分散している場合、Sagaオーケストレーションを実装するためにAWS Step Functionsを利用することができます。
AWSサービスを利用した実装
Sagaオーケストレーションパターンを実装するため、サンプルソリューションはStep Functionsの標準ワークフローを利用しています。

顧客がAPIを呼び出すと、Lambda関数が呼び出され、Lambda関数内で前処理が実行されます。関数はStep Functionsワークフローを開始し、分散トランザクションの処理を開始します。前処理が不要な場合は、Lambda関数を使わずにAPI Gatewayから直接Step Functionsワークフローを開始することができます。
Step Functionsの利用は、Sagaオーケストレーションパターンの実装に内在する単一障害点の問題を緩和します。Step Functionsにはフォールトトレランスが組み込まれており、各AWSリージョンの複数のアベイラビリティーゾーンにまたがってサービスキャパシティを維持し、個々のマシンやデータセンターの障害からアプリケーションを保護します。これにより、サービスそのものとそれが運用するアプリケーションワークフローの両方について高い可用性を確保することができます。
Step Functionsワークフロー
Step Functionsステートマシンを使用すると、パターン実装に必要な決定ベースの制御フローを構成することができます。Step Functionsワークフローは、注文発注、在庫更新、支払処理の各サービスを呼び出してトランザクションを完了させ、後続処理のためにイベント通知を送信します。Step Functionsワークフローは、トランザクションを調整するオーケストレータとして機能します。ワークフローでエラーが発生した場合、オーケストレータはサービス間でデータの整合性が維持されるように、補正トランザクションを実行します。
次の図は、Step Functionsワークフロー内で実行されるステップを示しています。Place Order、Update Inventory、Make Paymentの各ステップは、成功パスを表します。注文が発注され、在庫が更新され、支払いが処理された後、呼び出し元にSuccess状態が返されます。
Lambda関数Revert Payment、Revert Inventory、Remove Orderはワークフローのいずれかのステップが失敗した場合にオーケストレータが実行する補正トランザクションを表します。ワークフローが在庫更新ステップで失敗した場合、オーケストレータは呼び出し元にFail状態を返す前に在庫の巻き戻しステップと注文削除ステップを呼び出します。これらの補正トランザクションはデータの完全性が維持されることを保証します。在庫は元のレベルに戻り、注文は削除されます。
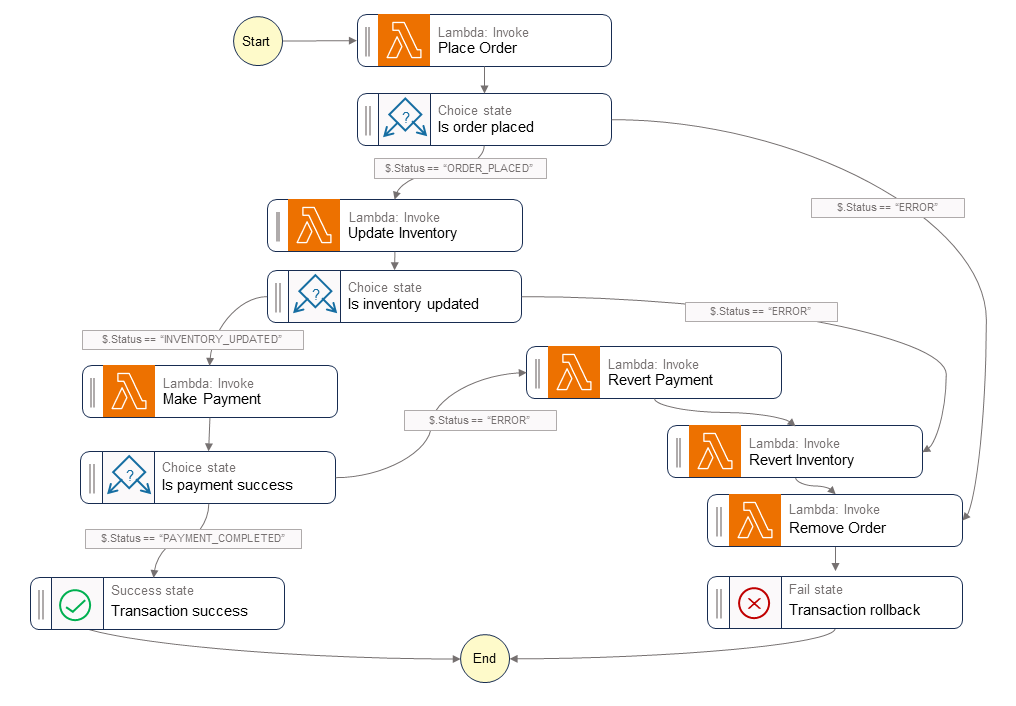
サンプルコード
以下のサンプルコードは、Step Functionsを使ってサーガオーケストレータを作成する方法を示しています。この例の実装全体を参照するにはGitHubリポジトリをご覧ください。
タスク定義
var successState = new Succeed(this,"SuccessState"); var failState = new Fail(this, "Fail"); var placeOrderTask = new LambdaInvoke(this, "Place Order", new LambdaInvokeProps { LambdaFunction = placeOrderLambda, Comment = "Place Order", RetryOnServiceExceptions = false, PayloadResponseOnly = true }); var updateInventoryTask = new LambdaInvoke(this,"Update Inventory", new LambdaInvokeProps { LambdaFunction = updateInventoryLambda, Comment = "Update inventory", RetryOnServiceExceptions = false, PayloadResponseOnly = true }); var makePaymentTask = new LambdaInvoke(this,"Make Payment", new LambdaInvokeProps { LambdaFunction = makePaymentLambda, Comment = "Make Payment", RetryOnServiceExceptions = false, PayloadResponseOnly = true }); var removeOrderTask = new LambdaInvoke(this, "Remove Order", new LambdaInvokeProps { LambdaFunction = removeOrderLambda, Comment = "Remove Order", RetryOnServiceExceptions = false, PayloadResponseOnly = true }).Next(failState); var revertInventoryTask = new LambdaInvoke(this,"Revert Inventory", new LambdaInvokeProps { LambdaFunction = revertInventoryLambda, Comment = "Revert inventory", RetryOnServiceExceptions = false, PayloadResponseOnly = true }).Next(removeOrderTask); var revertPaymentTask = new LambdaInvoke(this,"Revert Payment", new LambdaInvokeProps { LambdaFunction = revertPaymentLambda, Comment = "Revert Payment", RetryOnServiceExceptions = false, PayloadResponseOnly = true }).Next(revertInventoryTask); var waitState = new Wait(this, "Wait state", new WaitProps { Time = WaitTime.Duration(Duration.Seconds(30)) }).Next(revertInventoryTask);
GitHubリポジトリ
このパターンのサンプルアーキテクチャの実装全体は、GitHubリポジトリ https://github.com/aws-samples/saga-orchestration-netcore-blog をご確認ください。
参考ブログ
関連するコンテンツ
ストラングラーフィグパターン(Strangler fig pattern)
意図
ストラングラーフィグパターンは、モノリシックなアプリケーションをマイクロサービスアーキテクチャに段階的に移行し、変更リスクとビジネスの中断を軽減するのに役立ちます。
動機
モノリシックアプリケーションは、ほとんどの機能を単一のプロセスまたはコンテナ内で提供するように開発されています。コードは密結合しています。結果、アプリケーションを変更するにはリグレッションの問題を避けるために徹底的な再テストが必要になります。変更は分離してテストすることができず、サイクルタイムに影響します。アプリケーションがより多くの機能を持ってリッチになるにつれて、複雑性の高さはメンテナンスに費やす時間を増やし、市場投入までの時間を増やし、その結果として製品イノベーションを遅らせることになります。
アプリケーションの規模が大きくなるとチームの認識負荷が増大し、チームの所有権の境界が不明確になります。負荷に応じて個々の機能をスケーリングすることは不可能です—ピーク時の負荷をサポートするためにアプリケーション全体をスケーリングしなければなりません。システムが古くなると技術が陳腐化し、サポートコストが増大します。モノリシックでレガシーなアプリケーションは開発当時のベストプラクティスに従っており、分散するようには設計されていません。
モノリシックなアプリケーションをマイクロサービスアーキテクチャに移行すると、より小さなコンポーネントに分割できます。これらのコンポーネントは独立してスケールでき、独立してリリースでき、個々のチームが所有できます。その結果として変更が局所化されて迅速にテストしてリリースできるため、変更の速度が速くなります。コンポーネントが疎結合になり、個別にデプロイできるため、変更の影響範囲が小さくなります。
コードの書き直しやリファクタリングによってモノリスをマイクロサービスアプリケーションに完全に置き換えることは、大規模な仕事であり大きなリスクとなります。モノリスを一度に移行するビッグバンマイグレーションは、移行リスクとビジネスの中断を引き起こします。アプリケーションをリファクタリングしている間、新しい機能を追加することは非常に困難であり、不可能でさえあります。
この問題を解決する方法の1つは、Martin Fowlerが紹介したストラングラーフィグパターンを使うことです。このパターンでは、機能を抽出し、既存システムの周辺に新しいアプリケーションを作成して段階的にマイクロサービスに移行します。モノリスの機能は徐々にマイクロサービスに段階的に置き換えられ、アプリケーションのユーザーは新しく移行した機能を徐々に使えるようになる。すべての機能が新しいシステムに移行されると、モノリシックアプリケーションは安全に廃止することができます。
適用
ストラングラーフィグパターンを使うのは次の場合です:
- モノリシックなアプリケーションを徐々にマイクロサービス・アーキテクチャに移行したい場合
- モノリスのサイズと高い複雑性からビッグバン移行アプローチが危険な場合
- ビジネスは新機能を追加したいと考えており、移行が完了するまで待つことができない場合
- エンドユーザーは、移行中に最小限の影響しか受けないようにしなければならない場合
問題と注意事項
- コードベースへのアクセス:ストラングラーフィグパターンを実装するには、モノリスアプリケーションのコードベースにアクセスできなければなりません。モノリスから機能を移行する際には、マイナーなコード変更をおこない、新しいマイクロサービスに呼び出しをルーティングするための破損対策レイヤーをモノリス内に実装する必要があります。コードベースへのアクセスなしに呼び出しを傍受することはできません。コードベースへのアクセスは、リクエストをリダイレクトするためにも重要です―プロキシレイヤーが移行した機能のコールをインターセプトしてマイクロサービスにルーティングできるように、コードのリファクタリングが必要になるかもしれません。
- 不明確なドメイン:システムの早すぎる分解は、特にドメインが明確でない場合、コストがかかる可能性があり、サービス境界を間違える可能性があります。ドメイン駆動設計(DDD)はドメインを理解するための仕組みであり、イベントストーミングはドメインの境界を決定するためのテクニックであす。
- マイクロサービスの特定:マイクロサービスを特定するための重要なツールとしてDDDを使うことができます。マイクロサービスの特定には、サービスクラスの自然な分割箇所を探します。多くのサービスは独自のデータアクセスオブジェクトを所有し、簡単に切り離すことができます。関連するビジネスロジックを持つサービスや依存関係がないかほとんどないクラスは、マイクロサービスの良い候補となります。モノリスを分解する前にコードをリファクタリングし、密結合を防ぐことができます。また、コンプライアンス要件、リリース速度、チームの地理的位置、スケーリングニーズ、ユースケース駆動型テクノロジーのニーズ、チームの認知負荷なども考慮するべきです。
- 破損防止レイヤー:移行プロセス中、モノリス内の機能がマイクロサービスとして移行された機能を呼び出す必要がある場合、各呼び出しを適切なマイクロサービスにルーティングする破損防止レイヤー(ACL)を実装すべきです。モノリス内の既存の呼び出し元を分離して変更を不要とするため、ACLは呼び出しを新しいインタフェースに変換するアダプターまたはファサードとして機能します。このガイドのACLパターンの実装のセクションで詳しく説明しています。
- プロキシレイヤーの失敗:移行中、プロキシレイヤーはモノリシックなアプリケーションへのリクエストをインターセプトし、レガシーシステムか新しいシステムのどちらかにルーティングします。しかし、このプロキシレイヤーは単一障害点となったり、性能のボトルネックとなったりする可能性があります。
- アプリケーションの複雑さ:大規模なモノリスは最もストラングラーフィグパターンの恩恵を受けます。完全なリファクタリングの複雑性が低い小規模なアプリケーションの場合、アプリケーションを移行するのではなく、マイクロサービスアーキテクチャに書き直す方が効率的かもしれません。
- サービスの相互作用:マイクロサービスは同期的または非同期的に通信することができます。同期的通信が必要な場合、タイムアウトがコネクションやスレッドプールの消費を引き起こし、アプリケーションのパフォーマンスに問題が生じないかどうかを考慮します。そのような場合は、サーキットブレーカーパターンを利用して、長時間失敗する可能性のある操作に対して即座に失敗を返すようにします。非同期的通信は、イベントとメッセージングキューを利用することで実現できます。
- データの集約:マイクロサービスアーキテクチャでは、データはデータベースに分散されます。データ集約が必要な場合、フロントエンドではAWS AppSyncを、バックエンドではコマンド クエリ責務分離(CQRS)パターンを利用できます。
- データ整合性:マイクロサービスは個別にデータストアを所有しており、モノリシックアプリケーションもこのデータを使用する可能性があります。共有を可能にするには、キューとエージェントを使用することで、新しいマイクロサービスのデータストアをモノリシックアプリケーションのデータベースと同期させることができます。しかし、これは2つのデータストア間でデータの冗長性と結果整合性をもたらす可能性があるため、データレイクのような長期的なソリューションを確立できるまでの戦術的なソリューションとして扱うことを推奨します。
実装
ストラングラーフィグパターンでは、特定の機能を一度に1コンポーネントずつ新しいサービスやアプリケーションに置き換えていきます。プロキシレイヤーはモノリシックなアプリケーションへのリクエストをインターセプトし、レガシーシステムか新しいシステムのどちらかにルーティングします。プロキシレイヤーはユーザーを正しいアプリケーションにルーティングするため、モノリスが機能し続けることを保証しながら、新しいシステムに機能を追加することができます。新システムは最終的に旧システムのすべての機能に取って代わり、旧システムを廃止することができます。
高レベルアーキテクチャ
次の図では、モノリシックアプリケーションには3つのサービスがあります:Userサービス、Cartサービス、Accountサービスです。CartサービスはUserサービスに依存し、アプリケーションはモノリシックリレーショナルデータベースを使用します。

最初のステップでは、ストアフロントUIとモノリシックアプリケーションの間にプロキシレイヤーを追加します。初期ではモノリシックアプリケーションに全てのトラフィックをルーティングします。
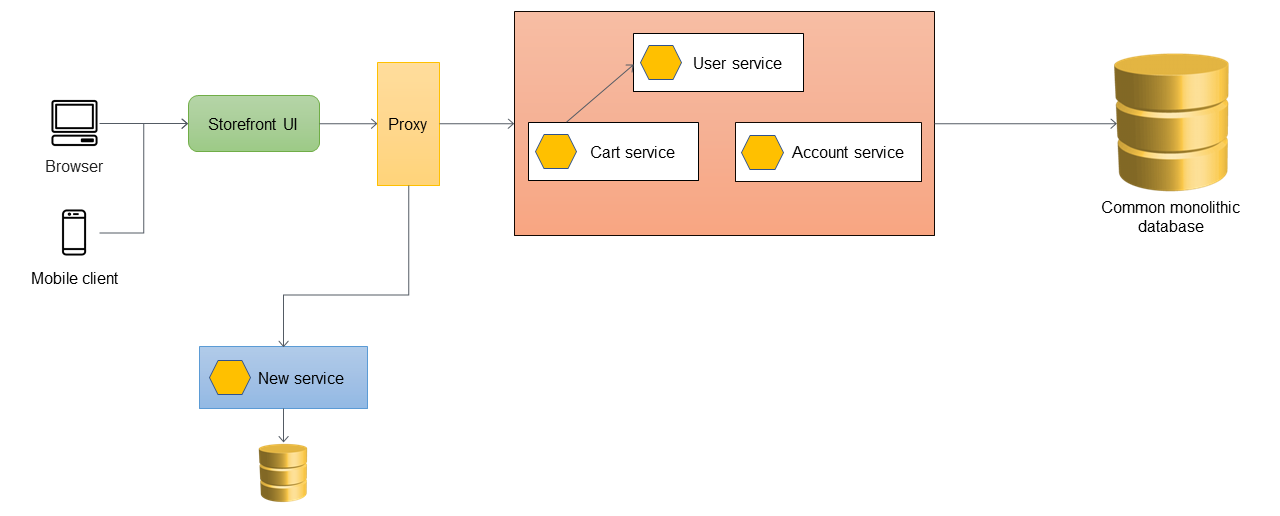
アプリケーションに新しい機能を追加したい場合、既存のモノリスに機能を追加する代わりに新しいマイクロサービスとして実装します。しかし、アプリケーションの安定性を保証するため、モノリスのバグ修正は続けます。以下の図では、プロキシレイヤーはAPI URLに基づいてモノリスまたは新しいマイクロサービスにルーティングします。
破損防止レイヤーの追加
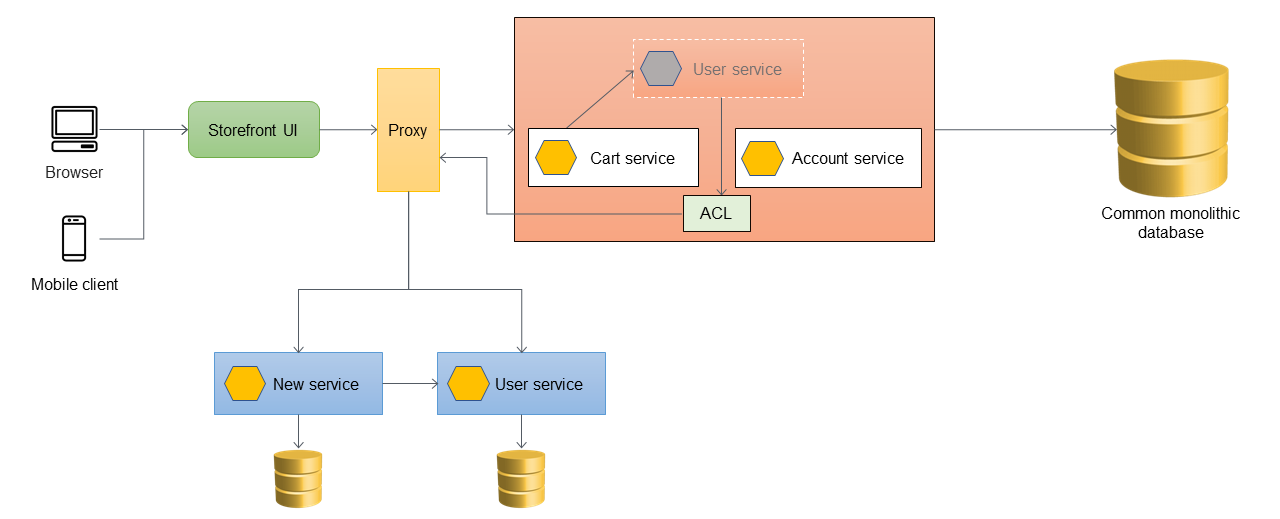
次のアーキテクチャでは、Userサービスはマイクロサービスに移行されています。CartサービスはUserサービスを呼び出しますが、その実装はモノリス内ではもはや利用できません。また、新しく移行されたサービスのインタフェースは、モノリシックアプリケーション内の過去のインタフェースと一致しないことがあります。これらの変更に対処するために、ACLを実装します。移行プロセス中、モノリス内の機能がマイクロサービスとして移行された機能を呼び出す必要がある場合、ACLは呼び出しを新しいインタフェースに変換し、適切なマイクロサービスにルーティングします。
例えば、UserServiceFacadeやUserServiceAdapterなどです。
移行されたサービス固有のクラスとしてモノリシックアプリケーション内部にACLを実装することができます;例えば、UserServiceFacadeやUserServiceAdapterです。ACLは、すべての依存サービスがマイクロサービスアーキテクチャに移行された後に廃止しなければなりません。
ACL を使用する場合、Cartサービスはモノリス内でUserサービスを呼び出し、UserサービスはACLを介してマイクロサービスに呼び出しをリダイレクトします。Cartサービスはマイクロサービスへの移行を意識することなく、Userサービスを呼び出します。この疎結合は、リグレッションとビジネスの中断を減らすために必要です。
データ同期処理
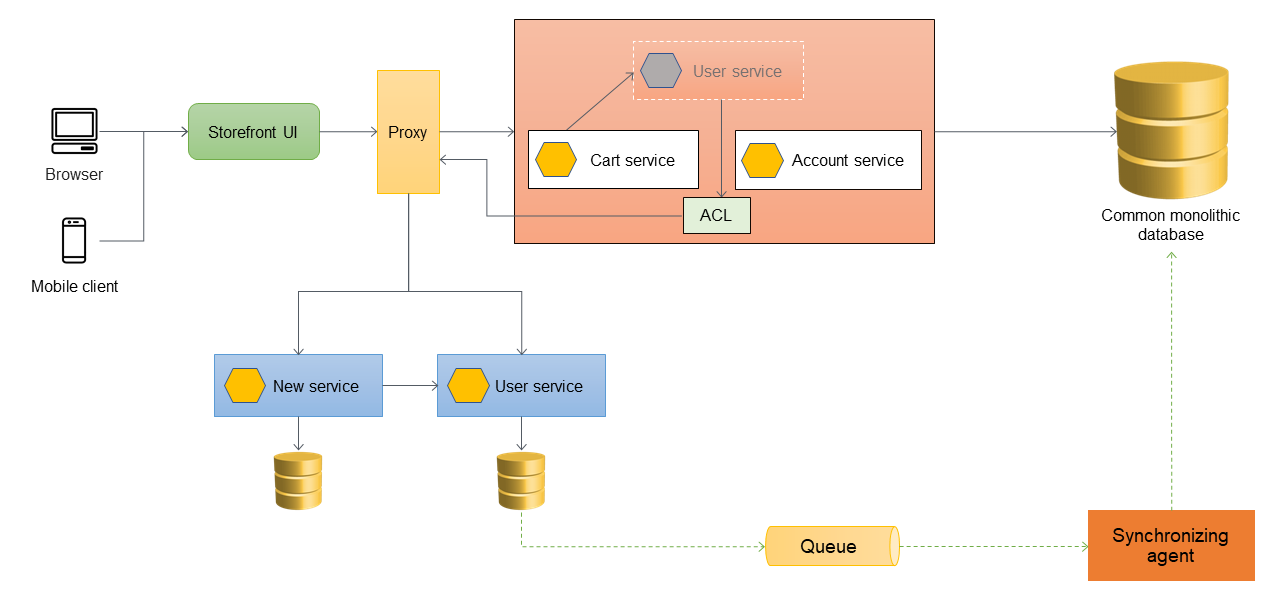
ベストプラクティスとして、マイクロサービスはデータを所有すべきです。Userサービスは独自のデータストアにデータを保存します。レポーティングのような依存関係を処理したり、マイクロサービスに直接アクセスする準備ができていない下流アプリケーションをサポートしたりするため、モノリシックデータベースとデータを同期する必要があるかもしれません。モノリシックアプリケーションは、まだマイクロサービスに移行していない他の機能やコンポーネントのデータも必要とするかもしれません。そのため、新しいマイクロサービスとモノリスの間でデータの同期が必要になります。データを同期するには、以下の図のように、ユーザマイクロサービスとモノリシックデータベースの間に同期エージェントを導入します。Userマイクロサービスは、データベースが更新されるたびにキューにイベントを送信します。同期エージェントはキューをリッスンし、モノリシックデータベースを継続的に更新します。モノリシックデータベースのデータは、同期されるデータに対して結果整合性が得られます。
更なるサービスの移行
Cartサービスがモノリシックアプリケーションのから移行した場合、そのコードが新しいサービスを直接呼び出すように修正され、ACLはもはやその呼び出しをルーティングしません。次の図ではそのアーキテクチャを示します。
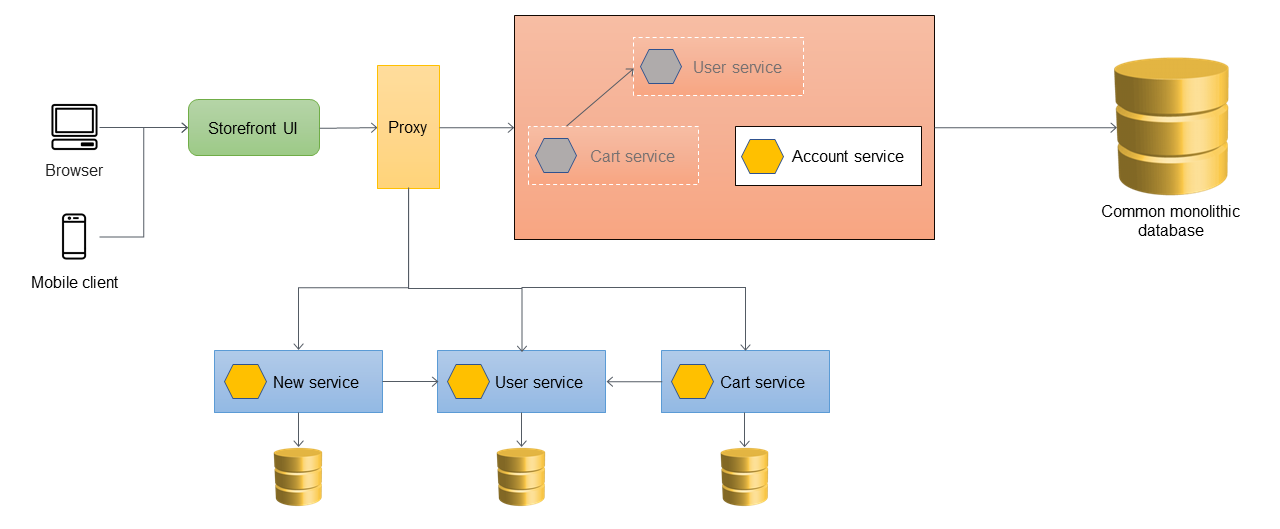
次の図は、すべてのサービスがモノリスから移行され、モノリスの骨組みだけが残った絞め殺された状態を示しています。過去のデータは、個々のサービスが所有するデータストアに移行されています。ACLは削除することができ、モノリスはこの段階で廃止する準備が整いました。
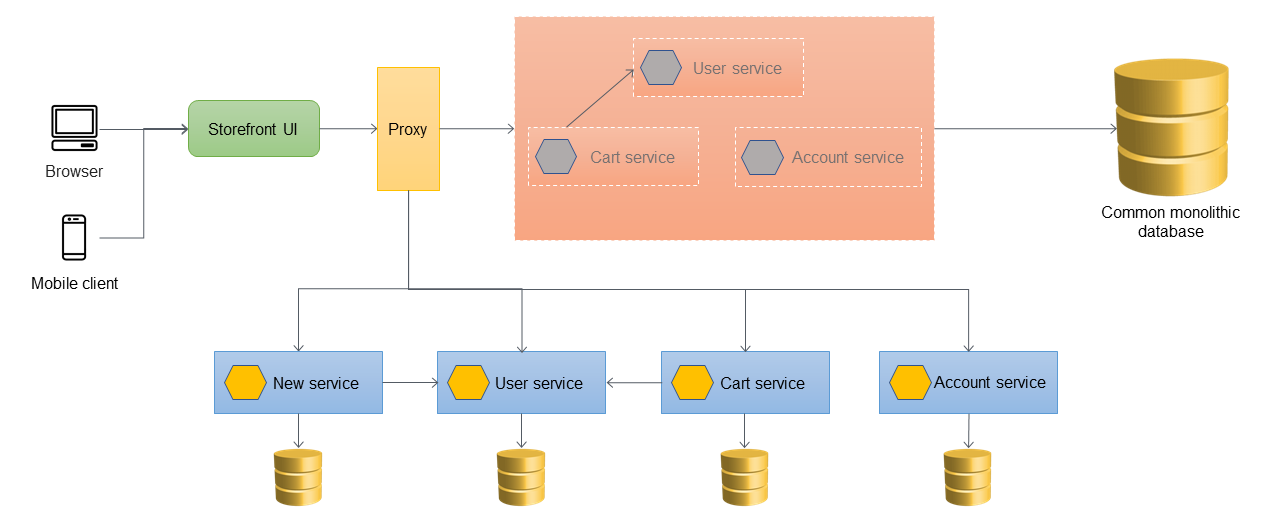
次の図は、モノリシックアプリケーションが廃止された後の最終的なアーキテクチャを示しています。アプリケーションの要件に応じ、リソースベースのURL(http://www.storefront.com/userのような)や独自ドメイン(例えばhttp://user.storefront.com)を使って個々のマイクロサービスをホストすることができます。ホスト名とパスを使用してHTTP APIを上流コンシューマに公開する主な方法の詳細については、APIルーティングパターンのセクションを参照してください。

AWSサービスを利用した実装
アプリケーションプロキシとしてAPI Gatewayを利用する
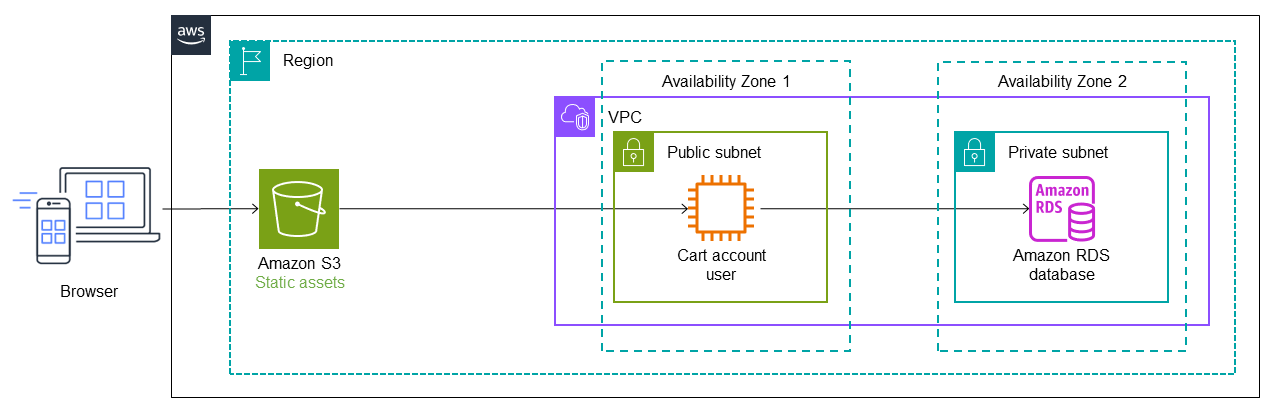
次の図は、モノリシックアプリケーションの初期状態を示しています。このアプリケーションはリフト・アンド・シフト戦略によってAWSに移行され、Amazon Elastic Compute Cloud(Amazon EC2)インスタンス上で実行され、Amazon Relational Database Service(Amazon RDS)データベースを使用していると仮定します。簡単にするために、アーキテクチャは1つのプライベートサブネットと1つのパブリックサブネットを持つ1つの仮想プライベートクラウド(VPC)を利用し、マイクロサービスは同じAWSアカウント内に最初にデプロイされると仮定します。(本番環境でのベストプラクティスは、デプロイの独立性を確保するためにマルチアカウントアーキテクチャを利用することです)。EC2インスタンスはパブリックサブネットの単一アベイラビリティゾーンに存在し、RDSインスタンスはプライベートサブネットの単一アベイラビリティゾーンに存在します。Amazon Simple Storage Service(Amazon S3)はウェブサイトのJavaScript、CSS、Reactファイルなどの静的アセットを保管します。
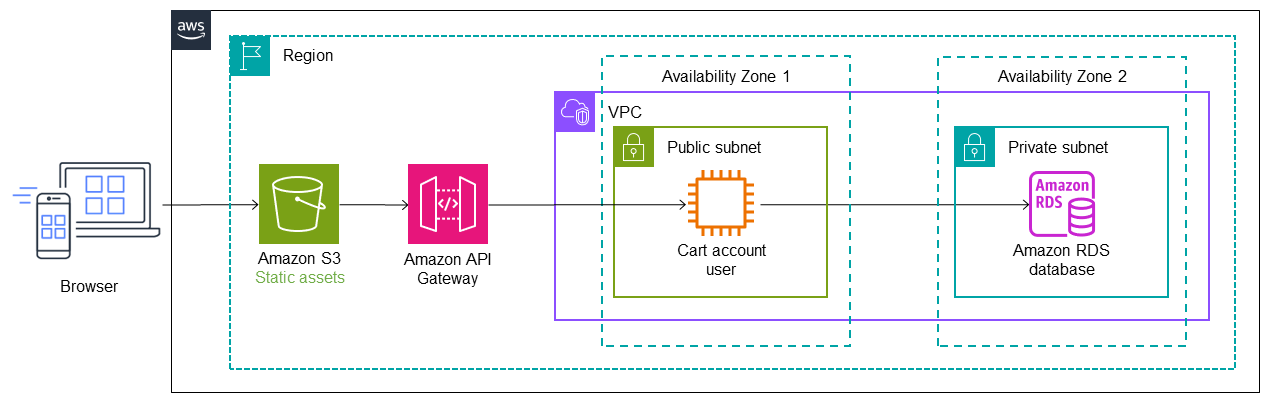
次のアーキテクチャでは、AWS Migration Hub Refactor Spacesがモノリシックアプリケーションの前にAmazon API Gatewayをデプロイしています。Refactor Spacesはアカウント内にリファクタリングインフラを作成し、API Gatewayはモノリスへのコールをルーティングするプロキシレイヤーとして機能します。最初は、全てのコールはプロキシレイヤーを通してモノリシックアプリケーションにルーティングされます。前述したように、プロキシレイヤーは単一障害点となる可能性があります。しかし、サーバーレスでマルチAZサービスであるAPI Gatewayをプロキシとして使うことでそのリスクを軽減できます。
UserサービスはLambda関数に移行され、Amazon DynamoDBデータベースがそのデータを保存します。LambdaのサービスエンドポイントとデフォルトルートがRefactor Spacesに追加され、呼び出しをLambda関数にルーティングするようにAPI Gatewayが自動的に設定されます。実装の詳細については、Iterative App Modernization Workshopのモジュール2を参照してください。

次の図では、CartサービスもモノリスからLambda関数に移行されています。追加のルートとサービスエンドポイントがRefactor Spacesに追加され、トラフィックは自動的にLambda関数Cartに切り替わります。Lambda関数のデータストアはAmazon ElastiCacheで管理されます。モノリシックアプリケーションには、未だにAmazon RDSデータベースと共にEC2インスタンスに残っています。

次の図では、最後のサービス(Account)がモノリスからLambda関数に移行されています。ここでは元のAmazon RDSデータベースを使い続けています。新しいアーキテクチャは、今や3つのマイクロサービスが個々にデータベースを所有しています。各サービスは異なるタイプのデータベースを利用しています。このように、マイクロサービスの特定のニーズを満たすために専用のデータベースを使用するというコンセプトはポリグロット永続化と呼ばれます。また、Lambda関数はユースケースに応じて異なるプログラミング言語で実装することができます。リファクタリングの際、Refactor SpacesはLambdaへのトラフィックのカットオーバーとルーティングを自動化します。これにより、構築者はルーティングインフラストラクチャのアーキテクチャ、デプロイ、設定に必要な時間を節約できます。

複数アカウントを利用する
前節の実装では、モノリシックアプリケーションのために1つのプライベートサブネットとパブリックサブネットを有する1つのVPCを使用し、単純化のために同じAWSアカウント内にマイクロサービスをデプロイしました。しかし、実際のシナリオではこのようなケースは稀で、マイクロサービスはデプロイの独立性のために複数のAWSアカウントにデプロイされることが多いです。複数アカウント構成では、モノリスから異なるアカウントの新サービスへのルーティングトラフィックを設定する必要があります。
Refactor Spacesは、モノリシックアプリケーションからAPIコールをルーティングするためのAWSインフラストラクチャの作成と設定を支援します。Refactor Spacesはアプリケーションリソースの一部として、API Gateway、Network Load Balancer、リソースベースのAWS Identity and Access Management(IAM)ポリシーをAWSアカウント内でオーケストレーションします。単一のAWSアカウントまたは複数のアカウントにまたがる新しいサービスを、外部のHTTPエンドポイントに透過的に追加できます。これらのリソース全てがAWSアカウント内でオーケストレーションされ、デプロイ後にカスタマイズしたり設定したりすることが可能です。
次の図のように、UserサービスとCartサービスが2つの異なるアカウントにデプロイされているとします。Refactor Spacesを使用する場合、サービスエンドポイントとルーティングを設定するだけです。Refactor SpacesはAPI Gateway―Lambda統合とLambdaリソースポリシーの作成を自動化するので、モノリスからサービスを安全にリファクタリングすることに集中できます。
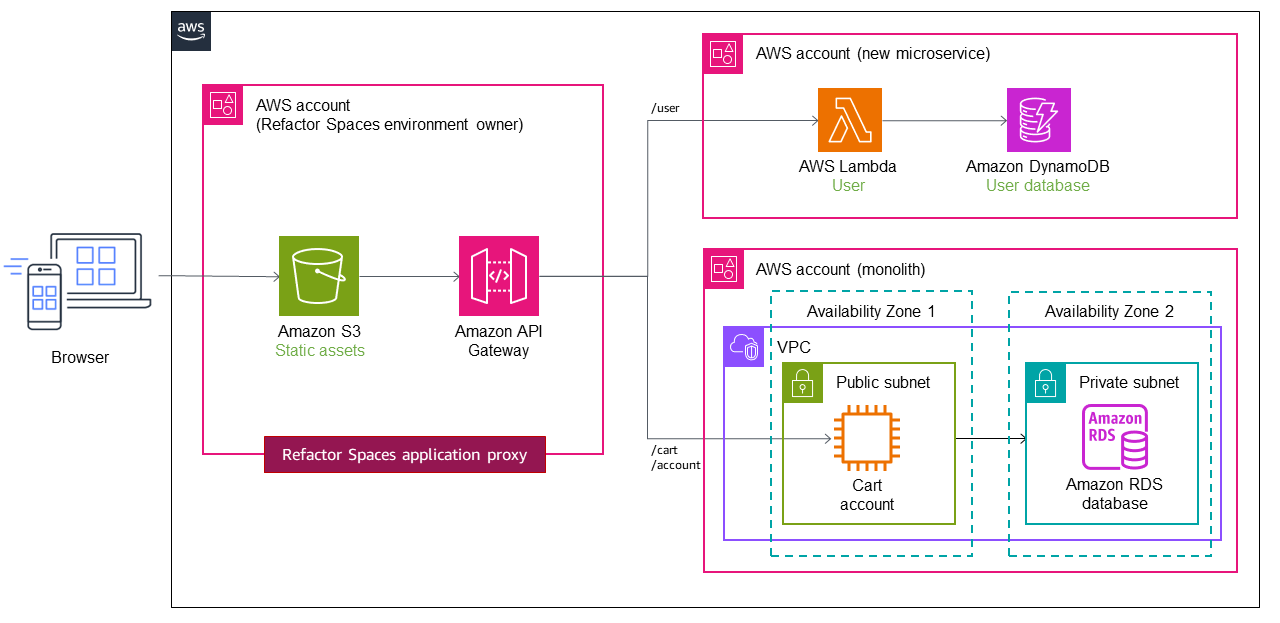
Refactor Spacesの使い方の動画チュートリアルには、Refactor Apps Incrementally with AWS Migration Hub Refactor Spacesをご覧ください。
ワークショップ
参考ブログ
- AWS Migration Hub Refactor Spaces
- Deep Dive on an AWS Migration Hub Refactor Spaces
- Deployment Pipelines Reference Architecture and Reference Implementations
関連するコンテンツ
トランザクショナルアウトボックスパターン(Transactional outbox pattern)
意図
トランザクショナルアウトボックスパターンは、分散システムにおいて1つの操作にデータベースへの書き込み操作とメッセージやイベント通知の両方が含まれる場合に発生する二重書き込み操作の問題を解決します。アプリケーションが2つの異なるシステムに書き込みをおこなう場合、二重書き込みが発生します;例えば、マイクロサービスがデータベースにデータを永続化し、他のシステムに通知するためにメッセージを送信する必要がある場合です。これらの操作のどちらかが失敗すると、データに矛盾が生じる可能性があります。
動機
マイクロサービスがデータベース更新後にイベント通知を送信する場合、データの整合性と信頼性を保証するため、これら2つのオペレーションはアトミックに実行されるべきです。
- データベースの更新が成功し、イベント通知が失敗した場合、下流サービスはその変更に気づかず、システムは整合性がない状態になります。
- データベースの更新が失敗し、イベント通知が送信された場合、データが破損し、システムの信頼性に影響を与える可能性があります。
適用
トランザクショナルアウトボックスパターンは次の場合に利用します:
- データベース更新がイベント通知を開始するようなイベント駆動アプリケーションを構築する場合
- 2つのサービスに関連する操作を原子性を保証したい場合
- イベントソーシングパターンを実装したい場合
問題と注意事項
- メッセージの重複:イベント処理サービスは重複したメッセージやイベントを送信する可能性があるため、処理されたメッセージを追跡してコンシューマサービスを冪等化することを推奨します
- 通知の順序:サービスがデータベースを更新するのと同じ順序で、メッセージやイベントを送信します。これは、データストアのポイントインタイムリカバリーのためにイベントストアを利用するイベントソーシングパターンにとって重要です。順序が正しくない場合、データの品質が損なわれる可能性があります。通知の順序が保持されない場合、結果整合性とデータベースのロールバックが問題を悪化させる可能性があります。
- トランザクションのロールバック:トランザクションがロールバックされた場合は、イベント通知を送信しないでください
- サービスレベルのトランザクション処理:トランザクションがデータストアの更新を必要とするサービスにまたがる場合、Sagaオーケストレーションパターンを利用して全てのデータストアでデータ完全性を維持します
実装
高レベルアーキテクチャ
以下のシーケンス図は、二重書き込み操作が発生したイベント順序を示しています。
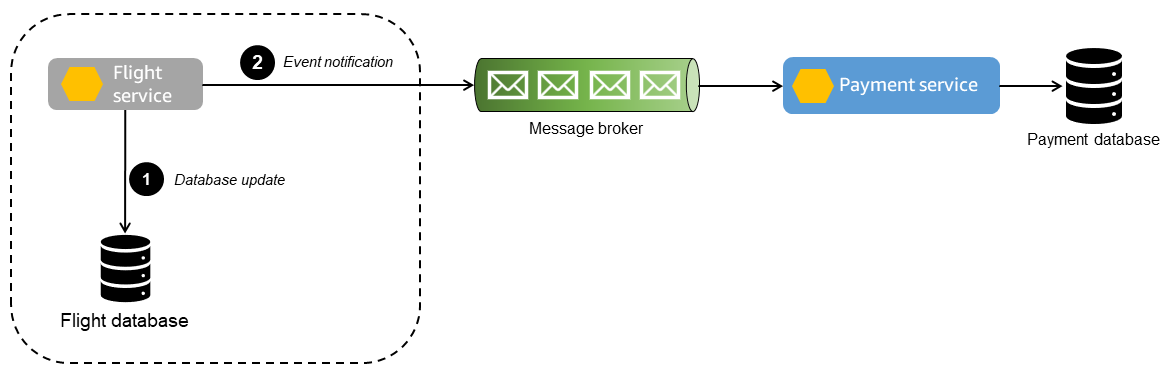
- Flightサービスはデータベースへの書き込み、Paymentサービスにイベント通知を送信します。
- メッセージブローカーは、メッセージとイベントをPaymentサービスに配信します。メッセージブローカーに障害が発生すると、Paymentサービスは更新を受信できなくなります。
Flightデータベースの更新に失敗しても通知が送信される場合、Paymentサービスはイベント通知に基づいて支払いを処理します。これは、下流のデータの不整合を引き起こします。
AWSサービスを利用した実装
シーケンス図でこのパターンを示すために、図で示しているように以下のAWSのサービスを利用します。
- AWS Lambdaを使ってマイクロサービスを実装します
- プライマリデータベースはAmazon Relational Database Service(Amazon RDS)で管理します
- Amazon Simple Queue Service(Amazon SQS)はイベント通知を受け取るメッセージブローカーとして機能します

トランザクションのコミット後にFlightサービスが失敗した場合、イベント通知は送られません。

しかし、トランザクションが失敗してロールバックしましたが、イベント通知が送信されてPaymentサービスで支払いが処理されるかもしれません。

ここでの問題に対応するには、アウトボックステーブルまたは変更データキャプチャ(CDC)を使うことができます。以下のセクションではこれら2つの選択肢について、そしてAWSサービスを使って実装するにはどのようにするのかについて議論します。
リレーショナルデータベースでアウトボックステーブルを利用する
アウトボックステーブルには、Flightサービスから全イベントがタイムスタンプとシーケンス番号とともに格納されます。
flightテーブルが更新されると、アウトボックステーブルも同じトランザクションで更新されます。別のサービス(例えば、Event processingサービス)がアウトボックステーブルを読み取り、Amazon SQSにイベントを送信します。Amazon SQSは後続処理のためにイベントに関するメッセージをPaymentサービスに送信します。Amazon SQSの標準的なキューは、メッセージが少なくとも1回は配信され、損失しないことを保証します。ただし、Amazon SQSの標準キューを使用する場合、同じメッセージまたはイベントが複数回配信される可能性があるため、イベント通知サービスが冪等である(つまり、同じメッセージを複数回処理しても悪影響がない)ことを保証する必要があります。メッセージに順序を付け、正確に一度だけ配信する必要がある場合、Amazon SQSの先入れ先出し(FIFO)キューを使用します。
flightテーブルの更新に失敗したり、アウトボックステーブルの更新に失敗したりした場合、トランザクション全体がロールバックされるため、下流でデータの不整合が発生することはありません。
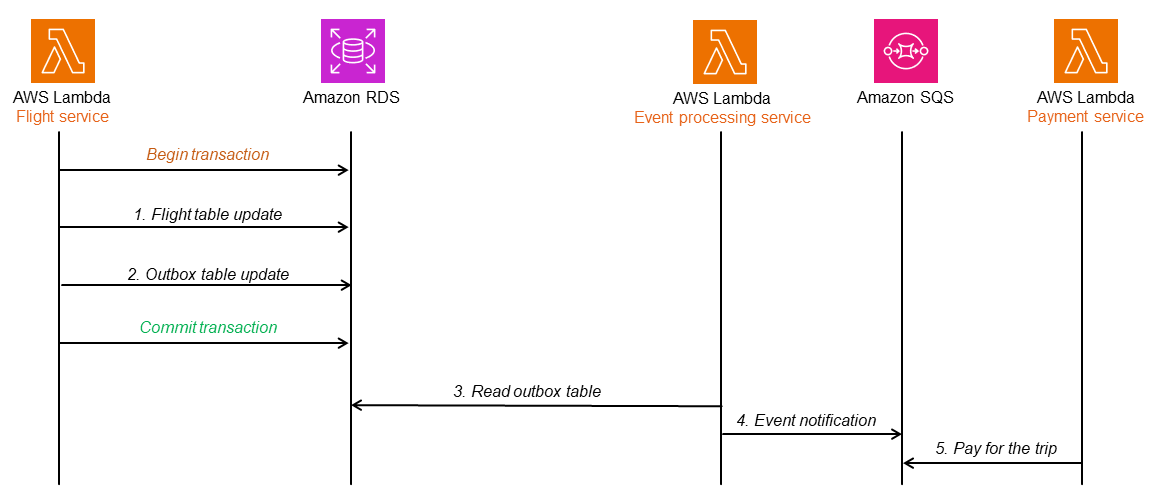
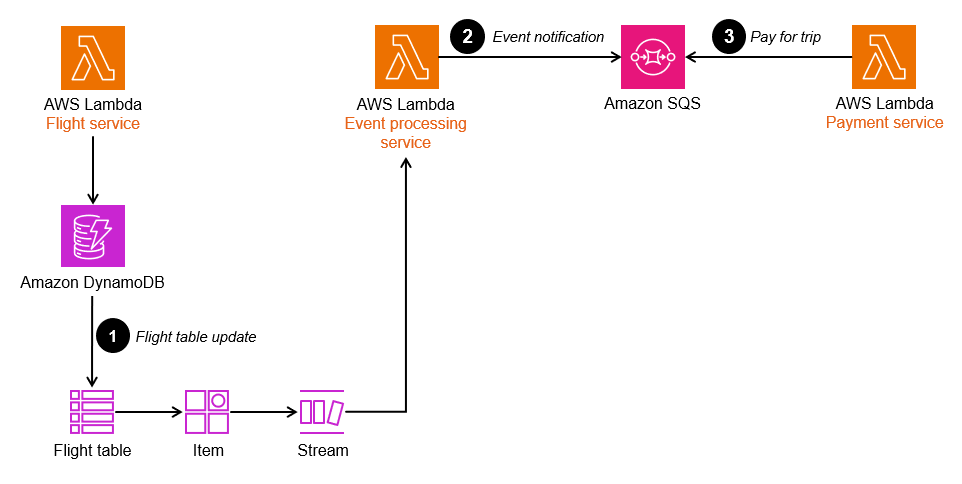
以下の図では、トランザクショナルアウトボックスアーキテクチャがAmazon RDSデータベースを使用して実装されています。Event processingサービスがアウトボックステーブルを読み取ると、コミットされた(成功した)トランザクションの行だけを認識してそのイベントのメッセージをSQSキューに入れ、Paymentサービスがそれを読み取ってさらに処理をおこないます。この設計は二重の書き込み操作の問題を解決し、タイムスタンプとシーケンス番号を使用することでメッセージとイベントの順序を保持します。
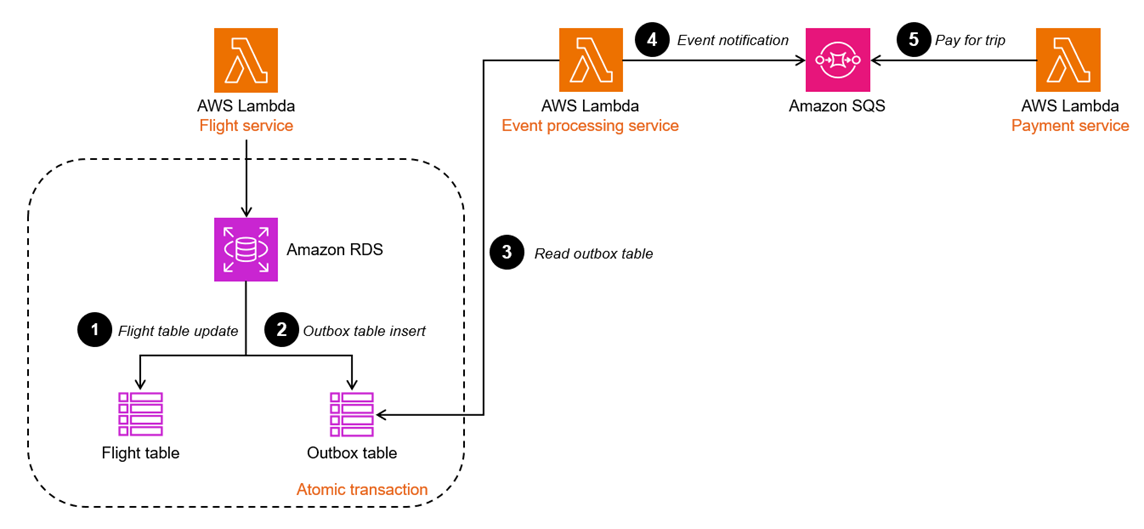
CDCを利用する
一部のデータベースは変更されたデータをキャプチャするために、アイテムレベルの変更の発行をサポートしています。変更されたアイテムを特定してイベント通知を送信することができます。これにより、更新を追跡するための別テーブルを作成するオーバーヘッドを節約できます。Flightサービスによって開始されたイベントは、同じアイテムの別の属性に格納されます。
Amazon DynamoDBはCDC更新をサポートするキーバリュー型のNoSQLデータベースです。次のシーケンス図では、DynamoDBはアイテムレベルの変更をAmazon DynamoDB Streamsに発行します。Event processingサービスはストリームから読み取り、処理をおこなうためにイベント通知をPaymentpサービスに発行します。
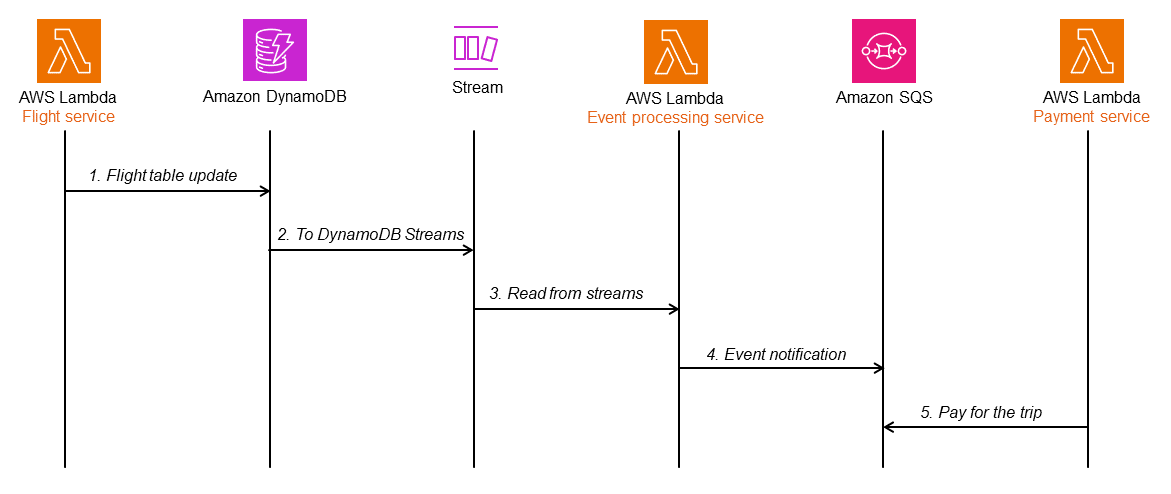
DynamoDB StreamsはDynamoDBテーブルのアイテムレベルの変更に関連するデータの流れを、時系列にしたシーケンスを利用してキャプチャします。
DynamoDBテーブルでストリームを有効にすることで、トランザクションアウトボックスパターンを実装できます。Event processingサービスのLambda関数は、これらのストリームに関連付けられます。
- flightテーブルが更新されると、変更されたデータがDynamoDB Streamsにキャプチャされ、Event processingサービスは新しいレコードがないかストリームをポーリングします。
- 新しいストリームレコードが利用可能になると、Lambda関数は同期的にイベントのメッセージをSQSキューに入れて処理をおこないます。実装の堅牢性を高めるため、必要に応じてタイムスタンプとシーケンス番号を取得する属性をDynamoDBアイテムに追加できます。
サンプルコード
以下のサンプルコードでは、アウトボックステーブルを利用してトランザクショなるアウトボックスパターンを実装する方法を示しています。コード全体を見るには、この例のGitHubリポジトリをご覧ください。
以下のコードスニペットでは、FlightエンティティとFlightイベントを、1つのトランザクション内でそれぞれのテーブルにデータベースに保存しています。
@PostMapping("/flights") @Transactional public Flight createFlight(@Valid @RequestBody Flight flight) { Flight savedFlight = flightRepository.save(flight); JsonNode flightPayload = objectMapper.convertValue(flight, JsonNode.class); FlightOutbox outboxEvent = new FlightOutbox(flight.getId().toString(), FlightOutbox.EventType.FLIGHT_BOOKED, flightPayload); outboxRepository.save(outboxEvent); return savedFlight; }
別のサービスが定期的にアウトボックステーブルをスキャンして新しいイベントを探し、Amazon SQSにそれらを送信し、Amazon SQSが正常に応答すればテーブルから削除することをおこないます。ポーリングレートはapplication.propertiesファイルで設定できます。
@Scheduled(fixedDelayString = "${sqs.polling_ms}") public void forwardEventsToSQS() { List<FlightOutbox> entities = outboxRepository.findAllByOrderByIdAsc(Pageable.ofSize(batchSize)).toList(); if (!entities.isEmpty()) { GetQueueUrlRequest getQueueRequest = GetQueueUrlRequest.builder() .queueName(sqsQueueName) .build(); String queueUrl = this.sqsClient.getQueueUrl(getQueueRequest).queueUrl(); List<SendMessageBatchRequestEntry> messageEntries = new ArrayList<>(); entities.forEach(entity -> messageEntries.add(SendMessageBatchRequestEntry.builder() .id(entity.getId().toString()) .messageGroupId(entity.getAggregateId()) .messageDeduplicationId(entity.getId().toString()) .messageBody(entity.getPayload().toString()) .build()) ); SendMessageBatchRequest sendMessageBatchRequest = SendMessageBatchRequest.builder() .queueUrl(queueUrl) .entries(messageEntries) .build(); sqsClient.sendMessageBatch(sendMessageBatchRequest); outboxRepository.deleteAllInBatch(entities); } }
GitHubリポジトリ
このパターンのサンプルアーキテクチャの実装全体は、GitHubリポジトリ https://github.com/aws-samples/transactional-outbox-pattern をご確認ください。
以上まで。
おわりに
今回のガイドはAWS 規範的ガイダンスというポータルサイトにまとめられているようです。 かなり記事の数が多いので、さらっと目を通すのは不可能ですね。 AWSできるひとの紹介か、何か特定のサービスについて知りたいといった目的をもったときに探すべきガイドだと思います。
また、AzureというかMicrosoftからも同じようにクラウドを利用したさいの設計パターン、デザインパターンについてまとめられたガイドが公開されています。
AWSのガイドと被っているパターンもありますが、Azureの方がパターンが多いです。 あと日本語なので読みやすいです。